だいぶ昔の話ですが、日本語テキストをネガ/ポジ分類するソフトウェアとして、scikit-learnを用いて『asari』を作り、Pythonパッケージとして公開したことがあります。作った自分でも存在をほぼ忘れていたのですが、ときどき使うことを試みる方がいて、Issueを上げてくれることがありました。そこで、重い腰を上げて、Issueをすべて解決し、v0.2.0をリリースしました。
asariの学習済みモデルはJoblibを用いて永続化していたのですが、scikit-learnのドキュメントにもあるように、保守性とセキュリティ面で課題がある状態でした。保守性の観点からいうと、この手法では、あるscikit-learnのバージョンで永続化したモデルが別のバージョンで動くとは限らず、動いたとしても結果が変わることもありえます。また、セキュリティ面では、読み込み時に悪意のあるコードが実行される可能性があります。
実際、Issueでは動かないという報告が上げられていました。そこで、再現性を担保したり異なる環境でも動くようにするため、学習済みモデルをONNX形式に変換して提供することにしました。ONNXは、機械学習モデルを表現するために構築されたオープンフォーマットのことを指します。異なる機械学習フレームワーク間でのモデルの変換を容易にしたり、モデルの移植性を向上させることを目的としています。今回は、学習環境とは異なる環境での予測に役立つと考えて採用しました。
scikit-learnのモデルをONNXに変換するためには、sklearn-onnxを使います。モデルの学習から推論までの大まかな手順は次のとおりです。
- scikit-learnでモデルを学習
- sklearn-onnxを用いて、モデルをONNX形式へ変換
- ONNX Runtimeを用いて推論
モデルの学習
まずはモデルを学習します。この辺はとくに難しいところはないでしょう。ただし、1つ注意点があります。asariの場合はトークン化にJanomeを使っているのですが、現状ではカスタムトークナイザーをONNX形式へ変換することはサポートされていません。そのため、TfidfVectorizerにトークナイザーを指定する代わりに、パイプラインの外側でトークン化をして、空白文字で結合しています。
from sklearn.calibration import CalibratedClassifierCV from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.svm import LinearSVC from asari.preprocess import tokenize X, y = load_jsonl(...) X = [tokenize(x) for x in X] x_train, x_test, y_train, y_test = train_test_split( X, y, test_size=0.1, random_state=42 ) pipe = Pipeline( [ ("vectorizer", TfidfVectorizer(ngram_range=(1, 2))), ("classifier", CalibratedClassifierCV(LinearSVC(), ensemble=False)), ] ) pipe.fit(x_train, y_train)
ONNX形式への変換
次に、学習したモデルをONNX形式に変換します。scikit-learnのモデルを変換するためには、次の2つの関数のうち、どちらかを使います。
convert_sklearnを使う場合、次のように、modelとinitial_typesの2つを必ず渡す必要があります。modelにはscikit-learnのモデルかパイプラインを渡します。initial_typesには入力の名前と型の情報を渡します。今回はテキストを入力するので、[('text', StringTensorType(None))]のようにしています。textは入力の名前であり、2番目の値は型と形状を表しています。1次元目は行数ですが、こちらは事前に予測できないためNoneにします。
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import StringTensorType initial_type = [('text', StringTensorType(None))] onx = convert_sklearn(pipe, initial_types=initial_type) with open("pipeline.onnx", "wb") as f: f.write(onx.SerializeToString())
to_onnxを使う場合、学習データセットのうちの1件を元に適切な型を推論します。convert_sklearnでは入力の名前と型を指定していたところを、次のように学習データセットの1行を渡します。asariでは、現時点ではこちらを使っています。
from skl2onnx import to_onnx onx = to_onnx(pipe, np.array(x_train)[1:]) with open("pipeline.onnx", "wb") as f: f.write(onx.SerializeToString())
残念ながら、TfidfVectorizerのONNX版はscikit-learn版と全く同じ結果を出力するわけではありません。現在のところ、tokenexpとseparatorsというパラメータを変換時に渡すことができます。実はこの辺の値を設定しておかないと、正規表現が自動的に置き換わって、日本語が上手く分割されなくなり、推論がデタラメになりました。今回は空白文字で区切った入力を与えているので、separatorsに空白だけを指定しています。
seps = {
TfidfVectorizer: {
"separators": [
" ",
],
}
}
onx = to_onnx(pipe, np.array(x_train)[1:], options=seps)
ONNX形式に変換できたら、Netronを使って可視化してみましょう。Netronはブラウザやデスクトップアプリで機械学習モデルを可視化できるツールです。変換したモデルをアップロードするだけで、次の画像のように、モデルの構造を可視化したりプロパティを確認できます。ONNX Optimizerなどでモデルを最適化した際に、変更箇所の確認やデバッグに使うと便利です。
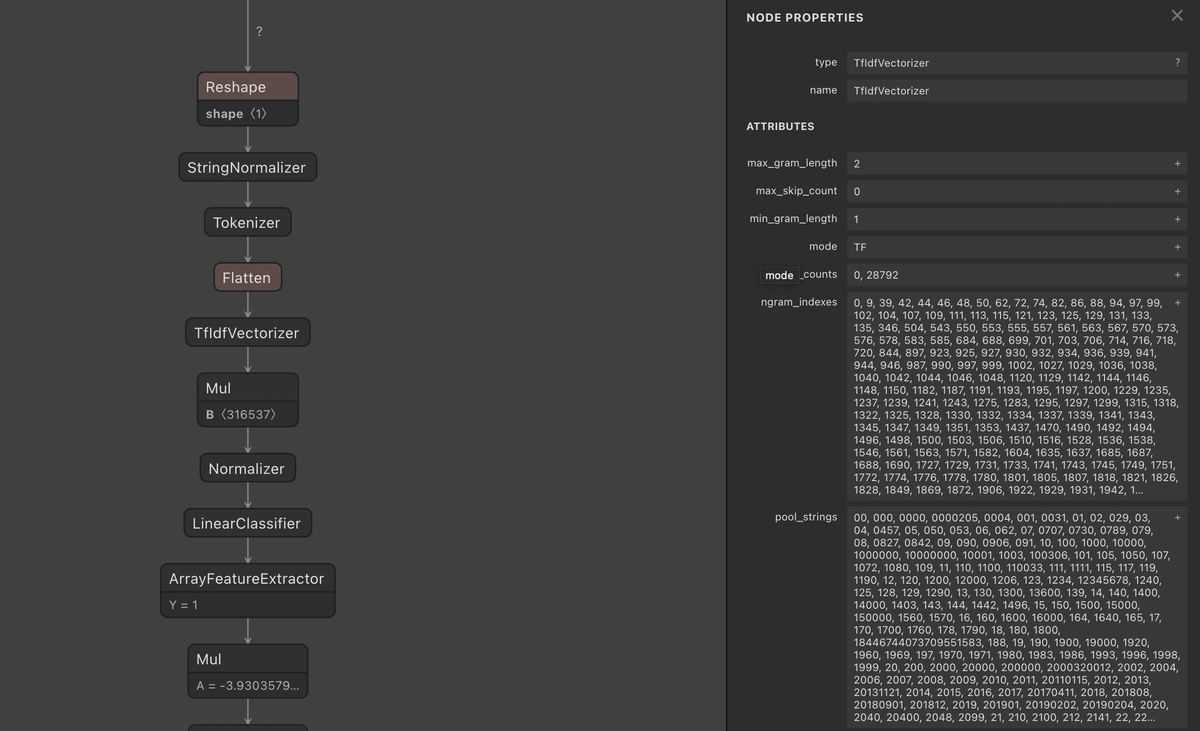
ONNX Runtimeによる推論
モデルをONNX形式に変換したら、ONNX Runtimeを使って推論します。カスタムトークナイザーはONNX形式に変換できなかったので、推論前に自分でトークン化しています。パイプラインに組み込めるのであれば、学習時と推論時で前処理(今回の場合はトークン化だけ)が一致するので、組み込んだほうがよいと思います。
import onnxruntime as rt sess = rt.InferenceSession("pipeline.onnx") input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name tokenized = tokenize(text) pred = sess.run([label_name], {input_name: [tokenized]})
確率値を得たい場合は次のようにします。
prob_name = sess.get_outputs()[1].name
proba = sess.run([prob_name], {input_name: [tokenized]})