言語処理学会の年次大会が始まるのでトレンドを時系列で分析してみた
2025年3月10日から言語処理学会の年次大会が開催されるため、聴講や予稿を読むのを楽しみにしています(毎年)。せっかくなので、自分でも何か手を動かして取り組んでみたいと思い、過去10年分の論文タイトルを取得し、クラスタリングとキーワード抽出をして時系列で可視化してみました。今回は、その手法と結果について紹介します。
大まかな流れとしては、以下の順番で説明します。
データセットの準備
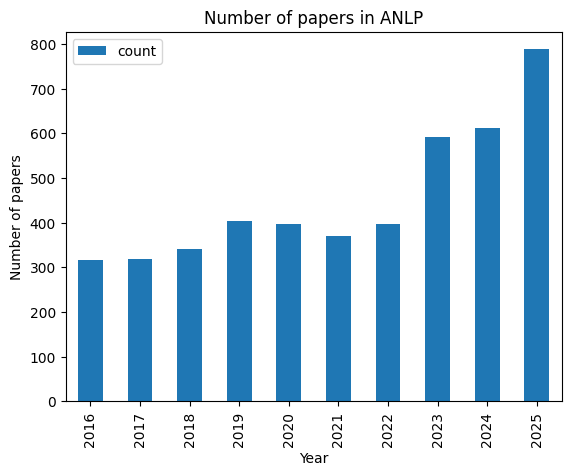
まずは、言語処理学会の年次大会のタイトルを収集します。タイトルは、論文の内容を表す重要な情報であり、クラスタリングの対象となるデータです。タイトルを収集するために、言語処理学会の年次大会のタイトルを取得します。今回は2016年から2025年までの10年分のタイトルを収集しました。年ごとのタイトルの件数を以下に示します。
次に、収集したタイトルを前処理します。収集したタイトルは、そのままでは後続の処理に適した形になっていない場合があるので前処理する必要があります。今回行った前処理の内容は以下の通りです。
- タイトルに含まれる改行を除去
- 英語のみのタイトルを除去
- 1つ以上のスペースが連続する場合に1つに集約
- 招待論文と総合討論という名前のタイトルを除去
- 同じ年に同じタイトルの論文がある場合に除去
タイトルの前処理が完了したら、形態素解析用の辞書を作成します。形態素解析は、テキストを形態素に分割する処理のことで、辞書を用いて行われます。形態素解析用の辞書に専門用語を登録しておくと、後ほどのキーワード抽出で専門用語を分割されていない形で抽出できます。人手でゼロから用意するのは大変なので、論文のタイトルをGPT-4oに入力し、登録すべき用語を抽出し、人手でフィルタリングしました。最終的には130語程度を登録しましたが、以下にその一部を示します。
機械翻訳 転移学習 固有表現認識 自然言語推論 大規模言語モデル ...
トレンドの可視化
トレンドを時系列で可視化するための手順の概要を以下に示します。まず、タイトルを埋め込みに変換し、次に次元削減を行います。次元削減した埋め込みをクラスタリングし、似た内容のグループ(トピックと呼ぶことにする)に分けます。その後、トピックを時間(今回の場合は年)ごとに分割し、c-TF-IDFを用いてキーワードを抽出して可視化します。
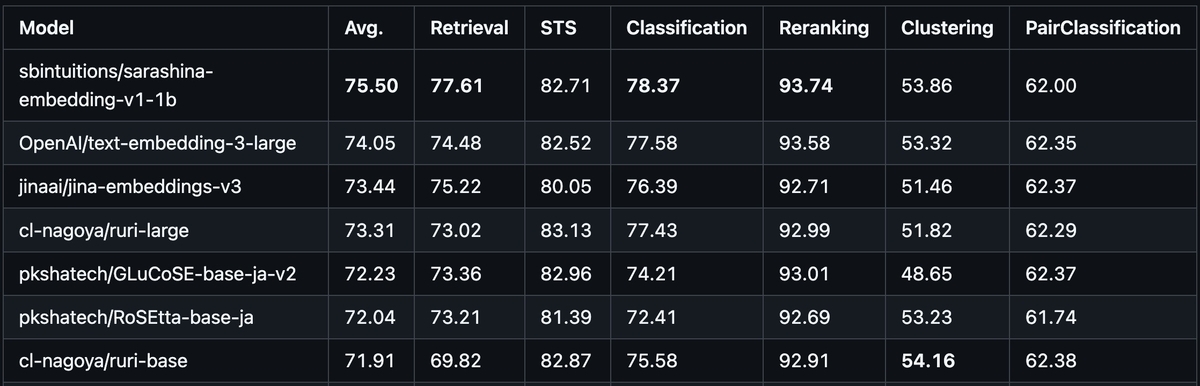
タイトルを埋め込みに変換するためのモデルとしては、Jina AIが公開しているjina-embeddings-v3を使用することにしました*1。このモデルは、多くの自然言語処理タスクで高い性能を発揮しており、多言語に対応しています。タスクに適した埋め込みを生成する機能があるのも特徴的で、クラスタリングにも対応しています。埋め込みモデルの性能についてはMTEBやJMTEBを参考にするとよいでしょう。
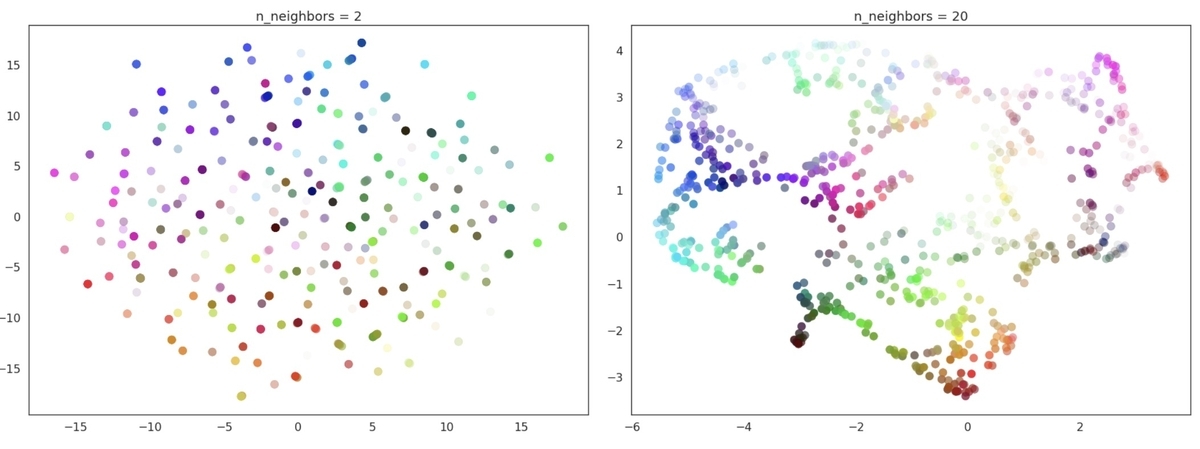
次に、UMAPを用いて埋め込みの次元数を削減します。UMAPは、高次元データを低次元に変換するためによく使われている手法です。UMAPはパラメーターの設定により局所的な構造と大域的な構造のどちらを重視するかのバランスをとることもできます。したがって、設定を調整することで、たとえば具体的な技術に関するクラスターを作りやすくするか、それともより大きなトピックに関するクラスターを作りやすくするかといったことを制御できます。
次元を削減したら、クラスタリングを行います。クラスタリングは、データをグループに分ける手法で、今回の場合は似た内容のタイトルをグループ化することが期待されます。クラスタリングのアルゴリズムはさまざまありますが、今回はk-meansを使用します。この方法ではクラスター数を事前に指定する必要があるため、クラスター数として25を設定しました。
クラスタリングを終えたら、c-TF-IDFを用いてキーワードを抽出します。c-TF-IDFは、クラスター版のTF-IDFで、クラスターごとに単語の重みを計算します。クラスターcにおける単語xの重みは以下のように計算できます。はクラスター
cにおける単語xの頻度、は単語
xの頻度、はクラスター当たりの平均単語数です。c-TF-IDFを用いることで、クラスターごとの重要な単語を抽出できます。
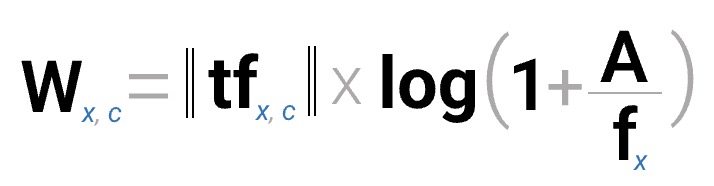
クラスタリングとキーワード抽出の結果を以下の表に示します。すべてのトピックについて表示すると長いので、上位5件のみを表示しています。結果を見ると、対話や言語モデル、翻訳、埋め込みに関するトピックが抽出されていることがわかります。トピック2については解釈がやや難しい結果となりました。また、形態素解析の辞書を作成したことで、専門用語が分割されずに抽出されていることも確認できます。
| トピック | カウント | 名前 | キーワード | 代表的なタイトル |
|---|---|---|---|---|
| 0 | 421 | 0_対話_発話_応答_対話システム | ['対話', '発話', '応答', '対話システム', '感情', '雑談対話', '生成', '推定', '会話', '評価'] | ['ユーザとの対話による発話・応答データ収集機構の検討', '日本語を対象とする感情を考慮した対話応答生成に関する研究', '生成と分類のマルチタスク学習による感情が考慮された対話応答生成'] |
| 1 | 396 | 1_大規模言語モデル_言語モデル_生成_推論 | ['大規模言語モデル', '言語モデル', '生成', '推論', '事前学習', 'モデル', '言語', '能力', '要約', 'タスク'] | ['固有表現抽出における大規模言語モデルを用いた自動アノテーション', '継続事前学習による日本語に強い大規模言語モデルの構築', '作って学ぶ日本語大規模言語モデル'] |
| 2 | 290 | 2_言語_性_英語_語 | ['言語', '性', '英語', '語', '日本語', '分析', '関係', '表現', '―', '意味'] | ['統語的複雑性指標を用いたL2日本語学習者エッセイ評価', '言い誤りの理解過程―日本語二重目的語構文の意味的整合性判断課題による検討―', 'L2日本語学習者によるエッセイ評価:語彙的多様性と文法的複雑性に焦点を置いて'] |
| 3 | 282 | 3_翻訳_機械翻訳_文法誤り訂正_評価 | ['翻訳', '機械翻訳', '文法誤り訂正', '評価', '誤り', '文', '品質', '自動', '統計', '対訳'] | ['文法誤り訂正における複数の逆翻訳モデルを利用した訂正傾向の比較', '翻訳における文パターンの利用', '日本語作文の自動誤り訂正における統計的機械翻訳とニューラル機械翻訳の性能評価'] |
| 4 | 264 | 4_単語_埋め込み_分散表現_bert | ['単語', '埋め込み', '分散表現', 'bert', '意味', '語義', 'ベクトル', '語義曖昧性解消', '述語項構造解析', '学習'] | ['文脈化された単語埋め込みの語義への単語頻度と語義分布の影響', '通時的な単語の意味変化を捉える単語分散表現の同時学習', '単語らしい文字n-gramの埋め込みによる単語の分散表現'] |
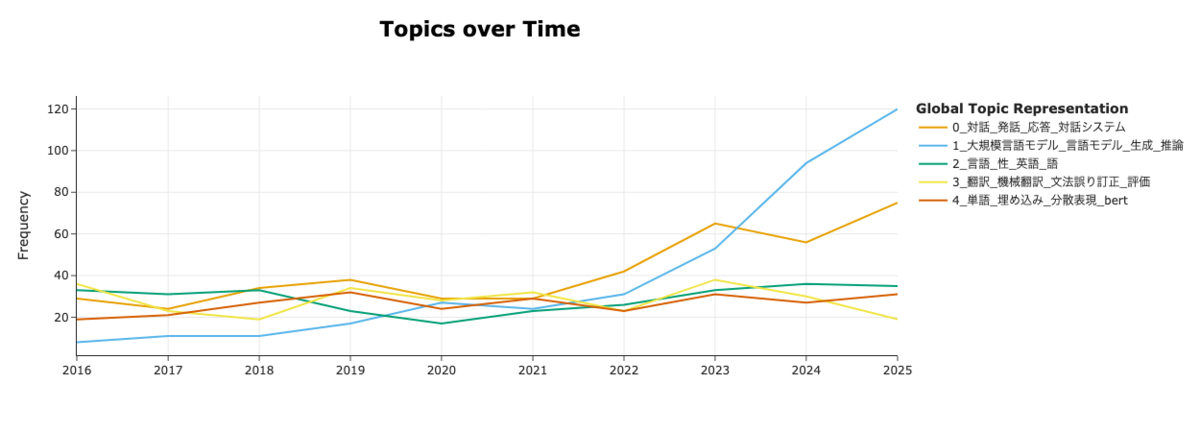
次に、上位5つのトピックに対して、時系列での可視化を行います。時系列での可視化は、各年ごとにトピックの件数を計算し、その件数をグラフにプロットすることで行っています。結果を見ると、言語モデルに関するクラスターが2022年以降から急激に伸びていることがわかります。ChatGPTの登場が2022年11月なので、その影響がありそうです。
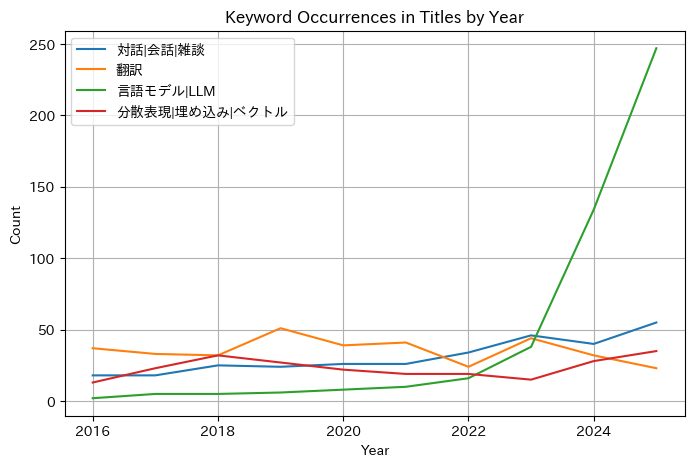
検算というわけでもないのですが、年ごとに指定したキーワードが出現する論文数を描画してみました。キーワードは凡例に表示したものをカウントしています。トピック2については、関連するキーワードを指定するのが難しかったので指定していません。1つの論文に複数のキーワードが含まれる場合もあるので、キーワードの出現数は論文数よりも多くなることがありえることに注意する必要があります。予想はしていましたが、言語モデルに言及した論文数が急激に増加していることがわかります。
おわりに
本記事では、言語処理学会年次大会の論文タイトルをクラスタリングし、時系列で可視化する方法について紹介しました。簡単な手法しか使っていませんが、この手法自体は言語処理学会の年次大会のタイトルだけでなく、ほかのことにも適用できます(トランプ大統領のTweetを時系列で分析するとか)。今回はクラスター数は固定でしたが、時とともに増減するようなモデルがあるのか興味が出てきたので、今後はそれについても調べてみたいと思います。