文書の解析をするためのPythonパッケージであるDoclingのドキュメントを何気なく眺めていたら、Picture classificationなる機能があることに気がついた。どうやら、文書中の画像を以下のカテゴリに分類できるようだ。
- 棒グラフ(bar_chart)
- バーコード(bar_code)
- 化学マークッシュ構造(chemistry_markush_structure)
- 化学分子構造(chemistry_molecular_structure)
- フローチャート(flow_chart)
- アイコン(icon)
- 折れ線グラフ(line_chart)
- ロゴ(logo)
- 地図(map)
- その他(other)
- 円グラフ(pie_chart)
- QRコード(qr_code)
- リモートセンシング(remote_sensing)
- スクリーンショット(screenshot)
- 署名(signature)
- スタンプ(stamp)
リポジトリのコードを掘っていくと、実態としてはEfficientNetをファインチューニングしたモデルであることがわかった。そのサイズ、なんとたったの16MB。以前に以下の記事で使ったモデルが5GBあることを考えると、圧倒的に小さい。これだけ小さいなら、会社の貧弱なラップトップでも動きそうだ。
そういうわけで試してみる。
準備
パッケージをインストールしておく。
pip install -q docling
画像の分類
モデルをダウンロードしたら、DocumentFigureClassifierPredictorにモデルのパスを渡してやる。今回はデバイスとしてCPUを指定しているが、GPUでも動作するはず。分類器を用意できたら、PillowのImageかNumPyの多次元配列のリストをpredictメソッドに渡すことでカテゴリを予測できる。
from docling.models.utils.hf_model_download import download_hf_model from docling_ibm_models.document_figure_classifier_model.document_figure_classifier_predictor import DocumentFigureClassifierPredictor from PIL import Image # モデルのダウンロード artifacts_path = download_hf_model( repo_id="ds4sd/DocumentFigureClassifier", revision="v1.0.1", local_dir=None, force=False, progress=True, ) # 分類器の用意 document_picture_classifier = DocumentFigureClassifierPredictor( artifacts_path=str(artifacts_path), device="cpu", num_threads=4 ) # 画像の読み込み filepath = "画像のパス.png" image = Image.open(filepath) # 予測 document_picture_classifier.predict(images=[image])
予測をすると、以下のようにスコア付きのカテゴリを出力してくれる。
[[('bar_chart', 0.9999836683273315), ('other', 1.614028587937355e-05), ('pie_chart', 1.0606347444763742e-07), ('map', 5.6198214082314735e-08), ('screenshot', 2.5053370933392216e-08), ('logo', 8.692216724170976e-09), ('bar_code', 4.440278367212613e-09), ('line_chart', 4.1925121152530664e-09), ('remote_sensing', 2.8389877115841955e-09), ('signature', 9.013164103954807e-10), ('flow_chart', 3.8304373561892646e-10), ('chemistry_markush_structure', 2.167793444751709e-10), ('icon', 1.7314336075990866e-10), ('stamp', 7.987029093659004e-11), ('qr_code', 1.940070847028519e-11), ('chemistry_molecular_structure', 1.0466177403911647e-11)],
4つの画像を分類した結果を次の表に示す。画像としては棒グラフ、折れ線グラフ、フローチャート、そして人間の画像を用意した。予測結果としては、もっともスコアの高いカテゴリを選んだ。結果を見ると、すべての画像が正しく分類されていることがわかる。
| 画像 | 種類 | 予測 |
|---|---|---|
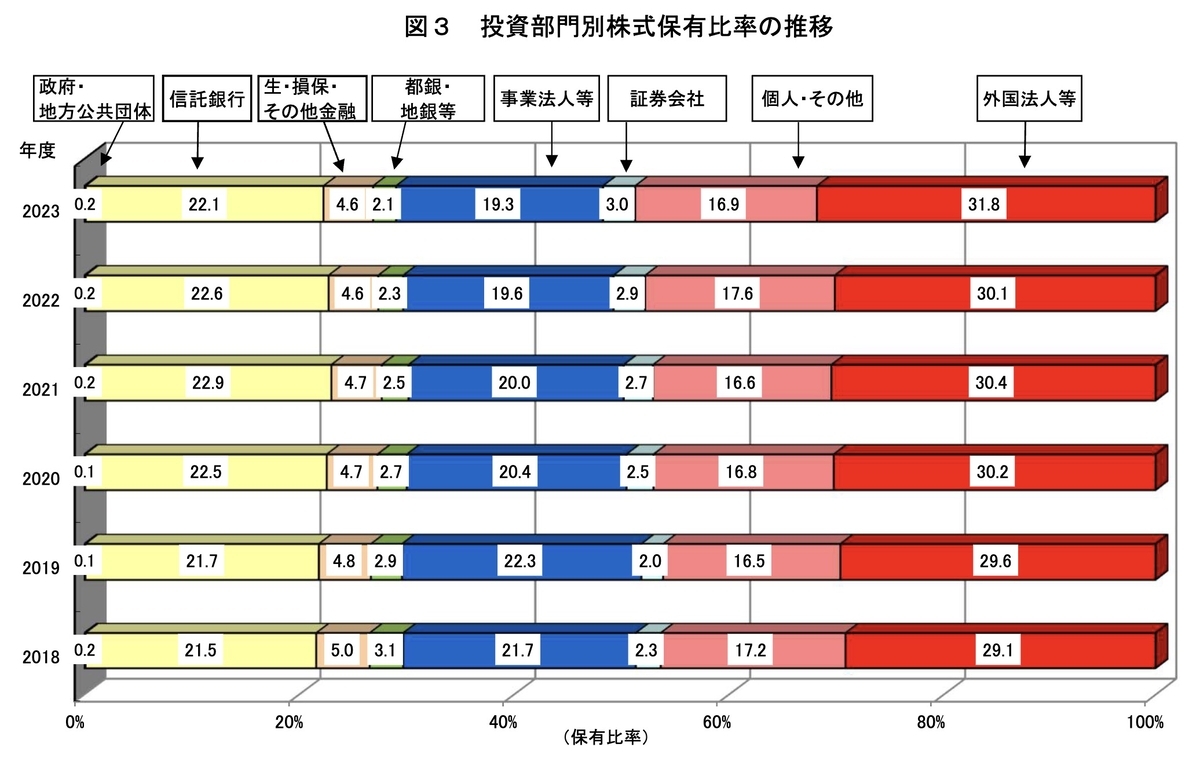 [4]より引用 |
棒グラフ | bar_chart |
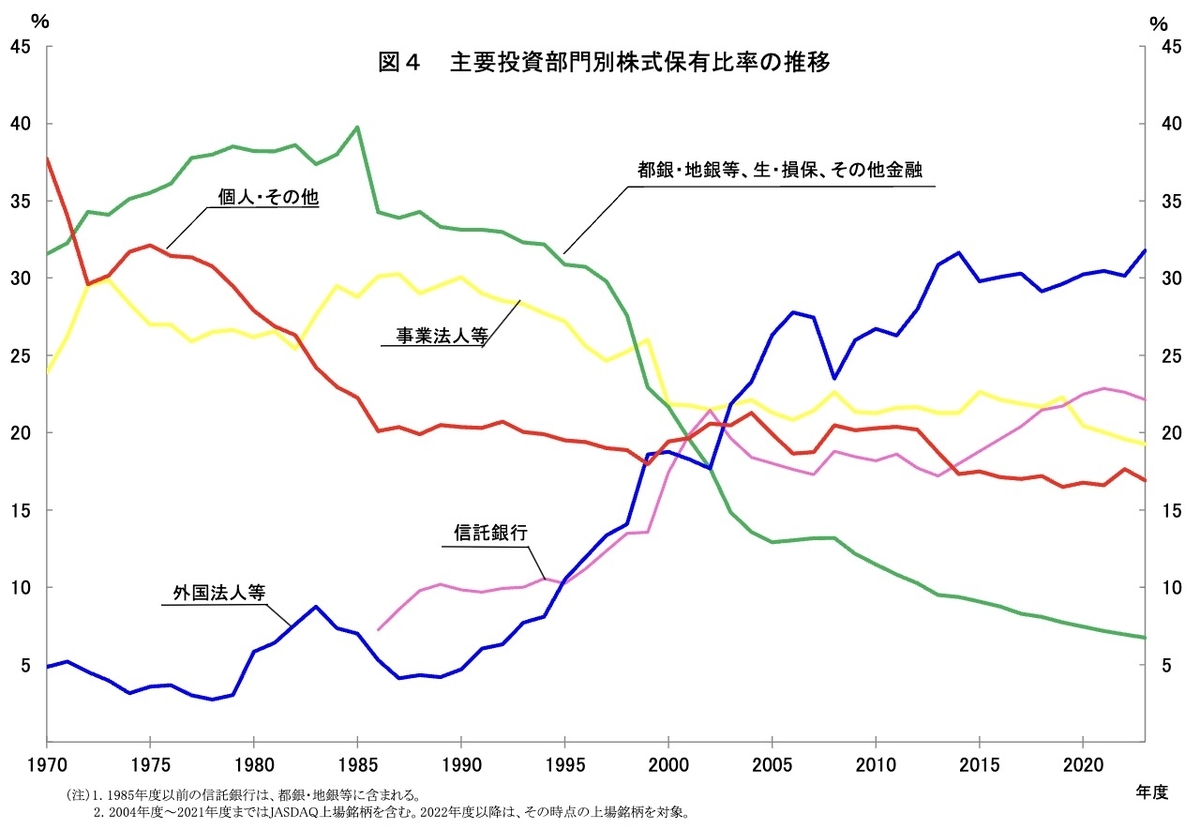 [4]より引用 |
折れ線グラフ | line_chart |
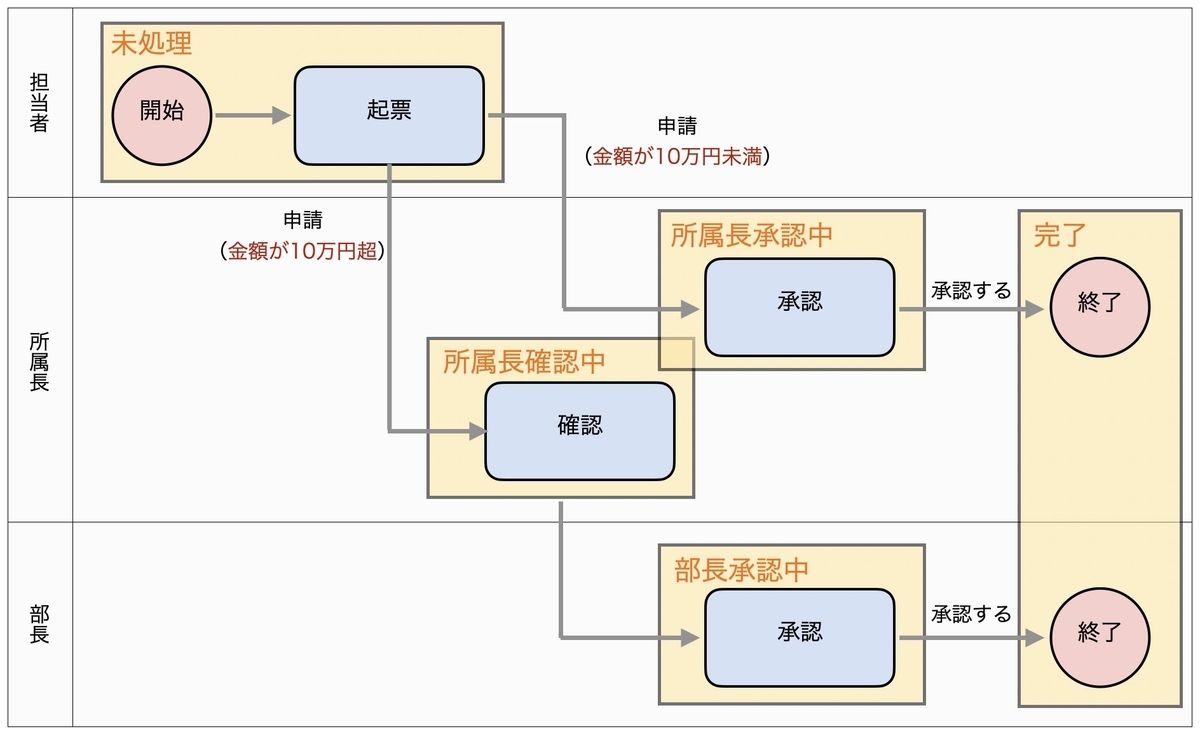 |
フローチャート | flow_chart |
 |
その他 | other |
CPUでも軽快に動作して素晴らしいのだが、残念なことに論文を見ても分類性能が書かれておらずよくわからなかった。Future workのところで、このモデルらしき機能に言及しているので、そのうちどこかで公開されることを願って気長に待つことにしよう。