冬休み中に日本語版のColBERTであるJaColBERTが公開されていたので試してみました。ColBERTは、論文を読んでいるときに名前が出てくることがあるので試してみたかったのですが、これで試せるようになりました。
ColBERTとは
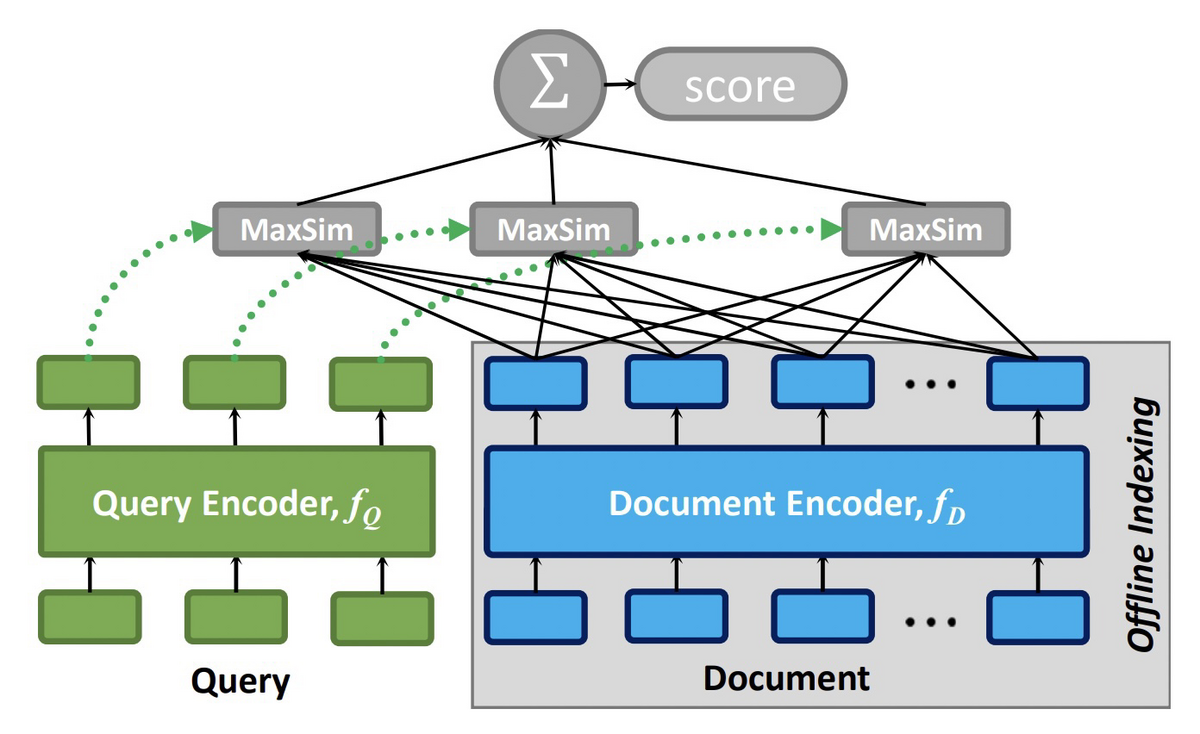
ColBERTは2020年に提案されたモデルで、以下の図に示すようなアーキテクチャになっています[1]。クエリと文書をそれぞれ別のエンコーダーで埋め込み、クエリ中の各トークンの埋め込みと文書の各トークンの埋め込みの間で最大類似度を計算し、その総和をスコアとしています。
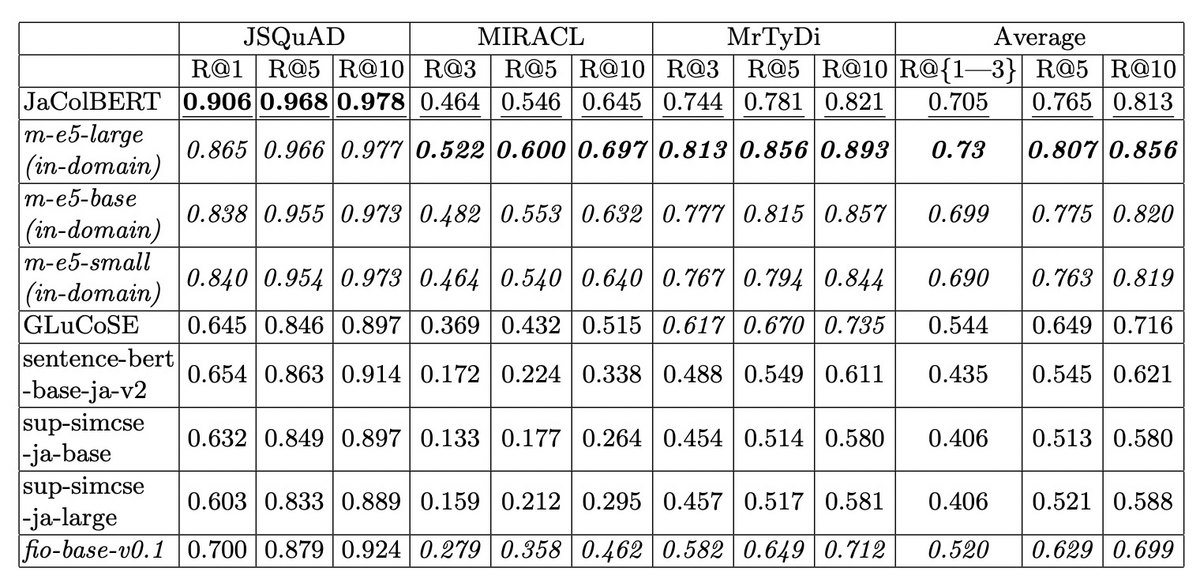
JaColBERTは、MS MARCOパッセージランキングデータセットを機械翻訳して作成した多言語版データセットであるmMARCOの日本語部分を用いて学習されています[2]。元のモデルとしては、東北大学が公開しているbert-base-japanese-v3を使用しています。多言語E5などとの比較結果は以下のとおりです。
インストール方法や使い方については、以下のページを参照してください。
実験設定
今回の実験では、日本語のQAデータセットを利用して、JaColBERTの検索性能を評価し、BM25やOpenAIのtext-embedding-ada-002と比較します。評価用のデータセットとしては、尼崎市のQAデータ[3]を使用し、評価指標としては上位10件のヒット率とMRR(Hit Rate@10、MRR@10)を使います。
実験結果
評価結果は以下のとおりです。JaColBERTの論文では、平均的な性能はmultilingual-e5-baseと同程度な結果となっていましたが、今回のデータセットでもそれに近い傾向となりました。
| モデル | Hit Rate@10 | MRR@10 |
|---|---|---|
| BM25 | 0.5918 | 0.3955 |
| multilingual-e5-base | 0.7679 | 0.5352 |
| multilingual-e5-large | 0.8457 | 0.6364 |
| JaColBERT | 0.7768 | 0.5694 |
| text-embedding-ada-002 | 0.8355 | 0.6436 |
参考資料
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- JaColBERT and Hard Negatives, Towards Better Japanese-First Embeddings for Retrieval: Early Technical Report
- FAQ Retrieval using Query-Question Similarity and BERT-Based Query-Answer Relevance
- RAGatouille | GitHub