近年、大規模言語モデル(LLM)の進化は、自然言語処理の分野において画期的な変化をもたらしています。とくに、OpenAIのGPT-4のようなLLMは、その応用範囲の広さと精度の高さで注目を集めており、多くの研究者や開発者が新たな利用方法を模索しています。本記事では、これらのLLMを活用したマルチクエリ生成が、文書検索の性能向上にどの程度効果があるかを検証します。
文書検索は、入力されたクエリに関連する文書を返してくれます。しかし、ユーザーが入力する単一のクエリでは、常に最適な検索結果が得られるとは限りません。そこで、LLMを用いてクエリを複数生成し、それらを組み合わせることで検索結果を改善する手法が登場しています[1]。このアプローチは、情報のニュアンスが複雑であったり、ユーザーが意図を正確に伝えるのが難しい場合に有効だと考えられます。
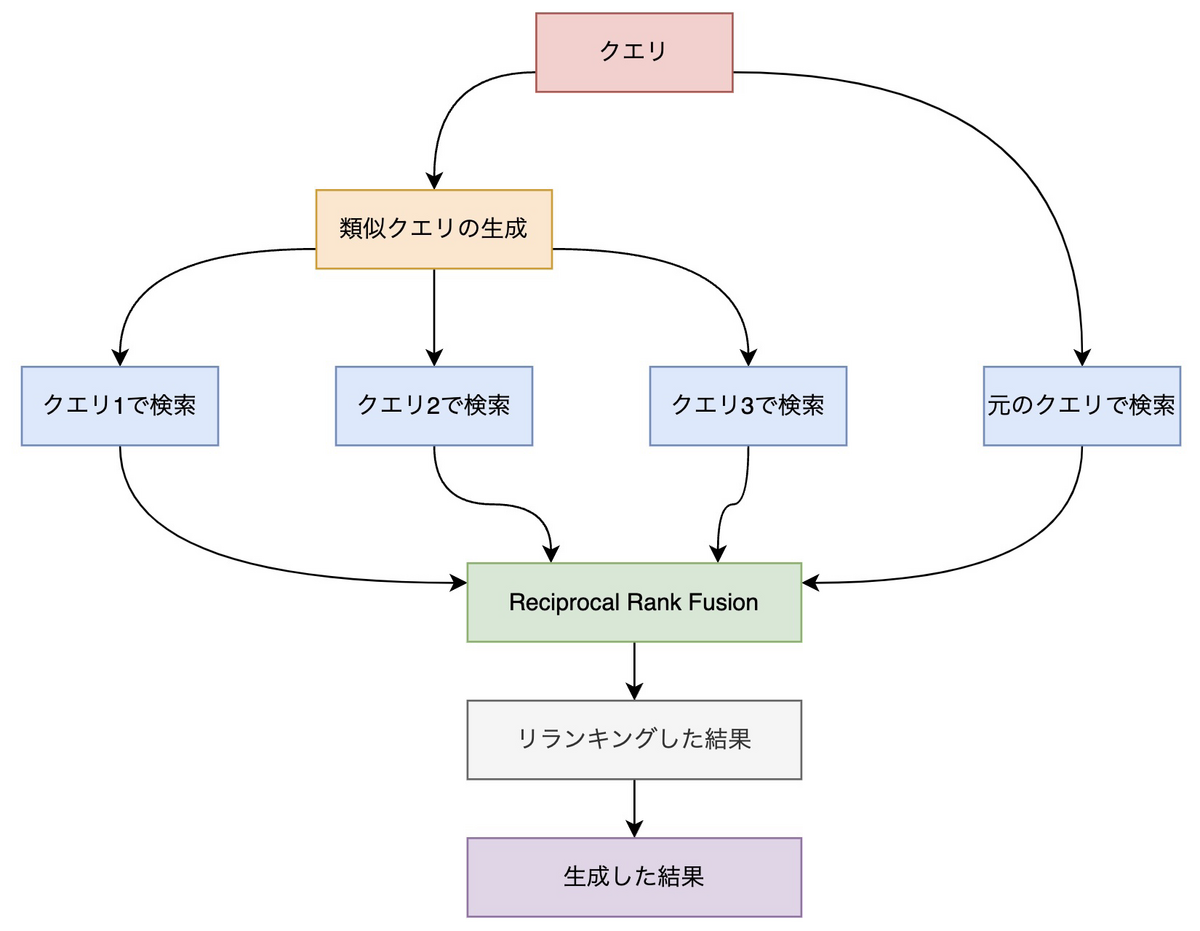
本実験では、GPT-3.5 Turboを利用して、元のクエリから派生する複数のクエリを生成し、検索結果をRRFによって統合したときの検索性能の検証結果を紹介します。このアプローチが、実際の検索シナリオでどのように機能するかを、日本語のQAデータセットを用いて評価しました。記事の構成は以下のとおりです。
実験設定
今回の実験では、LLMを用いて生成した複数のクエリを使うことで、検索性能が向上するか否かを検証します。クエリ生成にはGPT-3.5 Turboを使用し、元のクエリから3つのクエリを生成しています。なお、再現性を高めるために、GPT-3.5 Turboのtemperatureには0を設定しています。合計4つのクエリ(元のクエリ1つと生成したクエリ3つ)に対して文書を検索し、検索結果をRRFを使って統合します。
検索器としてはキーワード検索とベクトル検索を使用します。キーワード検索にはBM25、ベクトル検索にはOpenAIのtext-embedding-ada-002を使っています。どちらもLangChainの実装[2][3]を使用しており、BM25についてはパラメーターとしてk1に1.5、bに0.75を設定し、トークナイザーにはMeCabを採用しました。また、ベクターストアとしてはFAISSのデフォルト設定を採用しました。
評価用のデータセットとしては、尼崎市のQAデータ[4]を使用します。このデータセットには、784の質問に対して対応する回答がAからCの3つのカテゴリでラベル付けされています。Aの場合は正しい情報を含み、Bであれば関連する情報を含み、Cであればトピックが同じであることを意味します。今回はこれらのカテゴリを関連文書として扱うことにします。
評価については上位10件のヒット率とMRR(Hit Rate@10、MRR@10)でします。
実験結果
評価結果は以下のとおりです。キーワード検索とベクトル検索のどちらの場合でも、Hit Rate@10が改善するという結果になった一方、ベクトル検索の場合はMRR@10が若干ながら低下するという結果になりました。いくつかのクエリを見て分析する必要がありますが、関連する文書は返ってきているものの上位に表示されていないということなので、RRFによる結果の統合を見直すことで改善する可能性はありそうです。
| モデル | Hit Rate@10 | MRR@10 |
|---|---|---|
| BM25 | 0.5918 | 0.3955 |
| BM25 + Fusion | 0.6441 | 0.4398 |
text-embedding-ada-002 |
0.8355 | 0.6436 |
text-embedding-ada-002 + Fusion |
0.8520 | 0.6381 |
また、ほかの指標と合わせて検討する必要はありますが、ランキングが重要な場合は、以前の記事で検証したリランカーを入れることで改善する可能性があります。
実装の詳細
まずはプロンプトを定義します。このプロンプトでは、元のクエリをベースに、日本語のクエリを3つ生成するように指示しています。元々はLangChain Templatesのresearch-assistantで使われていたプロンプトですが、少し改変して利用しています。プロンプトについては改善の余地が大いにあると考えています。
template = (
"Write 3 google search queries in Japanese to search online that form an "
"objective opinion from the following: {question}\n"
"You must provide these alternative queries separated by newlines without a prefix number:"
"query 1\nquery 2\nquery 3"
)
prompt = PromptTemplate.from_template(template)
クエリによっては正しく生成されていないことがあるので、クリーニング用の関数を定義します。具体的には、クエリの前に番号が付与されているケースと、空文字列を含む場合が存在したため、それらを処理しています。
pattern = re.compile(r"^\d+. ") def clean_queries(queries: list[str]): queries = [pattern.sub("", query) for query in queries if query != ""] return queries
クエリ生成用のチェインを定義します。
generate_queries = (
prompt
| model
| StrOutputParser()
| (lambda x: x.split("\n"))
| clean_queries
)
RRF用の関数を定義します。ほぼ、LangChainのEnsembleRetrieverと同様の実装です。
def reciprocal_rank_fusion(doc_lists: list[list[Document]], k=60): rrf_score_dic = defaultdict(int) for docs in doc_lists: for rank, doc in enumerate(docs, start=1): rrf_score_dic[doc.page_content] += 1 / (rank + k) sorted_docs = sorted( rrf_score_dic.keys(), key=lambda x: rrf_score_dic[x], reverse=True ) page_content_to_doc_map = { doc.page_content: doc for doc_list in doc_lists for doc in doc_list } reranked_docs = [ page_content_to_doc_map[page_content] for page_content in sorted_docs ] return reranked_docs
最後に、これまで用意したコンポーネントを統合して、1つのチェインにします。
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda chain = ( {"generated": generate_queries, "original": RunnablePassthrough()} | RunnableLambda(lambda inputs: [inputs["original"]["question"]] + inputs["generated"]) | retriever.map() | reciprocal_rank_fusion )
以上で実装は完了です。