最近では、RAG(Retrieval Augmented Generation)を使って、検索して得られた文書を生成時に活用することがありますが、その性能を改善するための手法の1つとしてハイブリッド検索が知られています。ハイブリッド検索は、2つ以上の異なる検索技術を組み合わせた検索方法です。最近は、全文検索とベクトル検索の組み合わせを見ることが多く、その良いとこ取りをすることで検索性能を改善します。
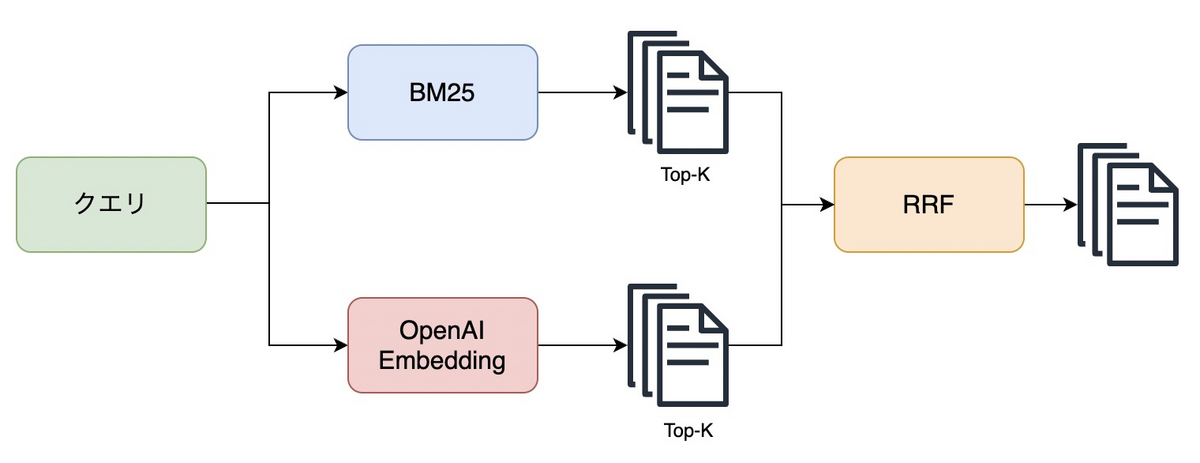
ハイブリッド検索の有効性はいたるところで報告されていますが、「適当に全文検索とベクトル検索を組み合わせるだけで性能が上がるのか?」というとそれには疑問があります。ハイブリッド検索では、全文検索とベクトル検索の結果をランク融合アルゴリズムを使って統合することが行われます。そのような仕組み上、どちらか片方の検索性能が低い場合、全体としての性能が下がることが考えられるはずです。
そこで本記事では、日本語のQAデータセットを利用して、ハイブリッド検索をしたときの検索性能の検証結果を紹介します。最初に、何も工夫せずに全文検索とベクトル検索を組み合わせた結果が性能を改善しないことがあることを示し、その次に全文検索を改善することでハイブリッド検索の性能が向上することを示します。記事の構成は以下のとおりです。
実験設定
今回の実験では、全文検索器とベクトル検索器をRRFを使って組み合わせることでハイブリッド検索器を構築し、日本語のQAデータセットを利用して、検索性能を評価します。
全文検索には、LangChainのBM25Retriever[1]およびAzure AI Searchを使用します。BM25RetrieverのトークナイザーにはMeCabを採用し、その他はデフォルト設定とします。Azure AI Searchにはアナライザーとしてja.luceneとja.microsoftを用意しました。一方、ベクトル検索にはOpenAIのtext-embedding-ada-002を使用し、ベクターストアとしてはFAISSのデフォルト設定を採用しました[2]。
評価用のデータセットとしては、尼崎市のQAデータ[3]を使用します。このデータセットには、784の質問に対して対応する回答がAからCの3つのカテゴリでラベル付けされています。Aの場合は正しい情報を含み、Bであれば関連する情報を含み、Cであればトピックが同じであることを意味します。今回はこれらのカテゴリを関連文書として扱うことにします。
評価については上位10件のヒット率とMRR(Hit Rate@10、MRR@10)でします。
実験結果
実験結果を以下に示します。全文検索ではスコアの計算にBM25を使っていますが、性能には違いがあることがわかります。BM25にはいくつかのバリエーションがあるので、その違いによる可能性もありますが、BM25のバリエーションによる性能差は小さいという研究結果[4]があることから考えると、トークン化やフィルタリングの違いによる性能差と考えられます。
ハイブリッド検索の性能を見ると、ベクトル検索だけの場合と比べて性能が低下するという結果になりました。結果を見ると、性能はja.lucene > ja.microsoft > LangChainの順なので、全文検索の性能に影響を受けていることがわかります。もちろん、すべての場合について当てはまる結果ではありませんが、ベクトル検索と全文検索を組み合わせればどんな場合でも性能が上がるという単純な話ではないことがわかりました。
| モデル | Hit Rate@10 | MRR@10 |
|---|---|---|
| BM25(LangChain) | 0.5918 | 0.3955 |
| BM25(ja.microsoft) | 0.5995 | 0.4055 |
| BM25(ja.lucene) | 0.6862 | 0.4649 |
| text-embedding-ada-002 | 0.8355 | 0.6440 |
| text-embedding-ada-002 + BM25(LangChain) | 0.7819 | 0.5855 |
| text-embedding-ada-002 + BM25(ja.microsoft) | 0.7997 | 0.5859 |
| text-embedding-ada-002 + BM25(ja.lucene) | 0.8252 | 0.6185 |
※実際のところ、検索システムを構築している人たちはチューニングしてから使うので、より良い結果が得られるはずです。ただ、ここではチューニングしない場合を対象にしています。実際、チューニングせずにハイブリッドにしているコードを見たことがあり、改善していなさそうでした。
全文検索の改善とその効果
というわけで、再考が求められます。
上記の結果より、単純なデフォルト設定の全文検索を使うのには問題がありそうなので、チューニングをし、性能を改善してからハイブリッド検索器を構築してみましょう。ここでは、上記の実験結果でもっとも性能が悪かったLangChainの検索器を対象に性能改善を試みることにします。
性能改善にはいくつかの観点が考えられますが、ここでは以下の観点から取り組みます。
- スコア計算
- 前処理
- 後処理
- ランク融合アルゴリズム
まずスコア計算についてですが、先ほどの実験ではBM25Retrieverを使いましたが、今回の実験ではTFIDFRetriever[5]に変更します。こちらは、TFIDFの値をもとにスコア計算をする検索器であり、内部的にはscikit-learnの実装が使われています。
次に前処理ですが、先ほどの実験で全文検索の中ではもっとも性能が高かったja.luceneのアナライザーを参考に、以下の処理をします。トークン化にはSudachi[6]を使用しており、分割モードにはもっとも短い単位であるAを使用しました。また、nGramの範囲には(1, 2)を設定しています。
- 基本形への変換
- 品詞による単語の除去
- 全角と半角の変換
- ストップワードの除去
- 小文字化
- その他正規化
- nGram
次の後処理では、リランカーを用いて、検索結果の再ランク付けをしています。リランカーについてもさまざまな選択肢が考えられますが、今回はbge-reranker-largeを採用しました[7]。このモデルは、XLM-RoBERTaをベースに主に中国語と英語のデータセットを使って作成されています。以下の記事での検証結果がもっとも良かったので、今回も有効だろうという判断です。
最後のランク融合アルゴリズムでは、今回採用したランク融合アルゴリズムであるRRFのハイパーパラメーターをチューニングしています。この値はデフォルトでは60ですが、今回は10としました。この値を変えることによる影響については以下の記事で説明しているので、気になる方は参照してください。
ここまでの処理を実装して評価した結果を以下に示します。改善版の全文検索は元のBM25と比べて性能が大きく改善していることがわかります。また、この全文検索をベクトル検索と組み合わせた結果を見ると、こちらも改善していることを確認できました。狙いどおり、全文検索の性能を改善することで、ハイブリッド検索の性能改善につながるという結果を示せました。
| モデル | Hit Rate@10 | MRR@10 |
|---|---|---|
| BM25(LangChain) | 0.5918 | 0.3955 |
| 改善版の全文検索 | 0.8189 | 0.5615 |
| text-embedding-ada-002 | 0.8355 | 0.6440 |
| text-embedding-ada-002 + BM25(LangChain) | 0.7819 | 0.5855 |
| text-embedding-ada-002 + 改善版 | 0.8954 | 0.6616 |
おわりに
本記事では、全文検索でデフォルトの設定を使った場合とチューニングした場合にハイブリッド検索へ与える影響を示しました。結果としては、当初の疑問どおり、単に全文検索とベクトル検索を組み合わせるだけでは性能は上がらず、全文検索をチューニングすることで性能が向上しました。今回取り組んだ以外にも、全文検索やベクトル検索の性能や結果の統合の仕方を改善する方法はさまざま存在するので、ハイブリッド検索を採用する際には、それらの施策とセットで取り組みたいと思います。
参考資料
- BM25Retriever | LangChain
- Vector store-backed retriever
- FAQ Retrieval using Query-Question Similarity and BERT-Based Query-Answer Relevance
- Which BM25 Do You Mean? A Large-Scale Reproducibility Study of Scoring Variants
- TFIDFRetriever | LangChain
- Sudachi: a Japanese Tokenizer for Business
- C-Pack: Packaged Resources To Advance General Chinese Embedding