意味的知識グラフとApache Solrを使った関連語検索の実装
Manningから出版予定の『AI-Powered Search』(AIを活用した情報検索の意)を冬休み中に読んでいたら、その中で意味的知識グラフ(Semantic Knowledge Graph)と呼ばれるデータ構造について説明していて、関連語の計算やクエリ拡張などに使えるということで興味深かったので紹介しようと思います。最初に意味的知識グラフについて説明したあと、日本語のデータセットに対して試してみます。

本記事の構成は以下のとおりです。
意味的知識グラフとは
知識グラフと聞くと、固有表現認識や関係抽出、OpenIEを使って構築するグラフを思い浮かべる方もいると思うのですが、意味的知識グラフはそれとは異なります。後ほど説明しますが、知識グラフが明示的に構築されるのに対し、意味的知識グラフは検索エンジンの索引を作成することで自動的に構築されます。検索エンジンはクエリに関連する文書を見つけ、ランク付けするのに対し、意味的知識グラフはクエリに関連する単語(フレーズでもよい)を見つけ、ランク付けする検索エンジンとみなせます。
意味的知識グラフを使うことでどのようなことができるかについて本に載っていた例を使って説明します。たとえば、健康に関する文書集合から索引を作成し、鎮痛剤である「advil」を検索した場合、通常の検索エンジンであれば「advil」という単語を含む文書を返しますが、意味的知識グラフであれば以下に挙げたような「advil」に関連する単語を関連度とともに返すことができます。本には、これらの単語を使って、適合率と再現率を考慮しつつクエリ拡張する方法が紹介されています。
| 単語 | 関連度 | 補足 |
|---|---|---|
| advil | 0.71 | アメリカで市販されているイブプロフェン系の鎮痛解熱剤 |
| motrin | 0.60 | イブプロフェン系の鎮痛解熱剤 |
| aleve | 0.47 | アメリカで市販されているナプロキセン系の解熱・鎮痛剤 |
| ibuprofen | 0.38 | 非ステロイド系の解熱、鎮痛、抗炎症薬 |
| alleve | 0.37 | おそらくaleveのスペルミス |
意味的知識グラフは検索エンジンの基礎となる転置インデックスを用いて実現します。つまり、検索エンジンに文書をインデックスすれば使えるということです。具体的には、以下の図の右に示す転置インデックスと真ん中に示す順方向インデックスで構築します。転置インデックスと順方向インデックスで文書と単語のマッピングの方向が異なりますが、このような双方向のマッピングがグラフの探索や関係の発見において重要になります。
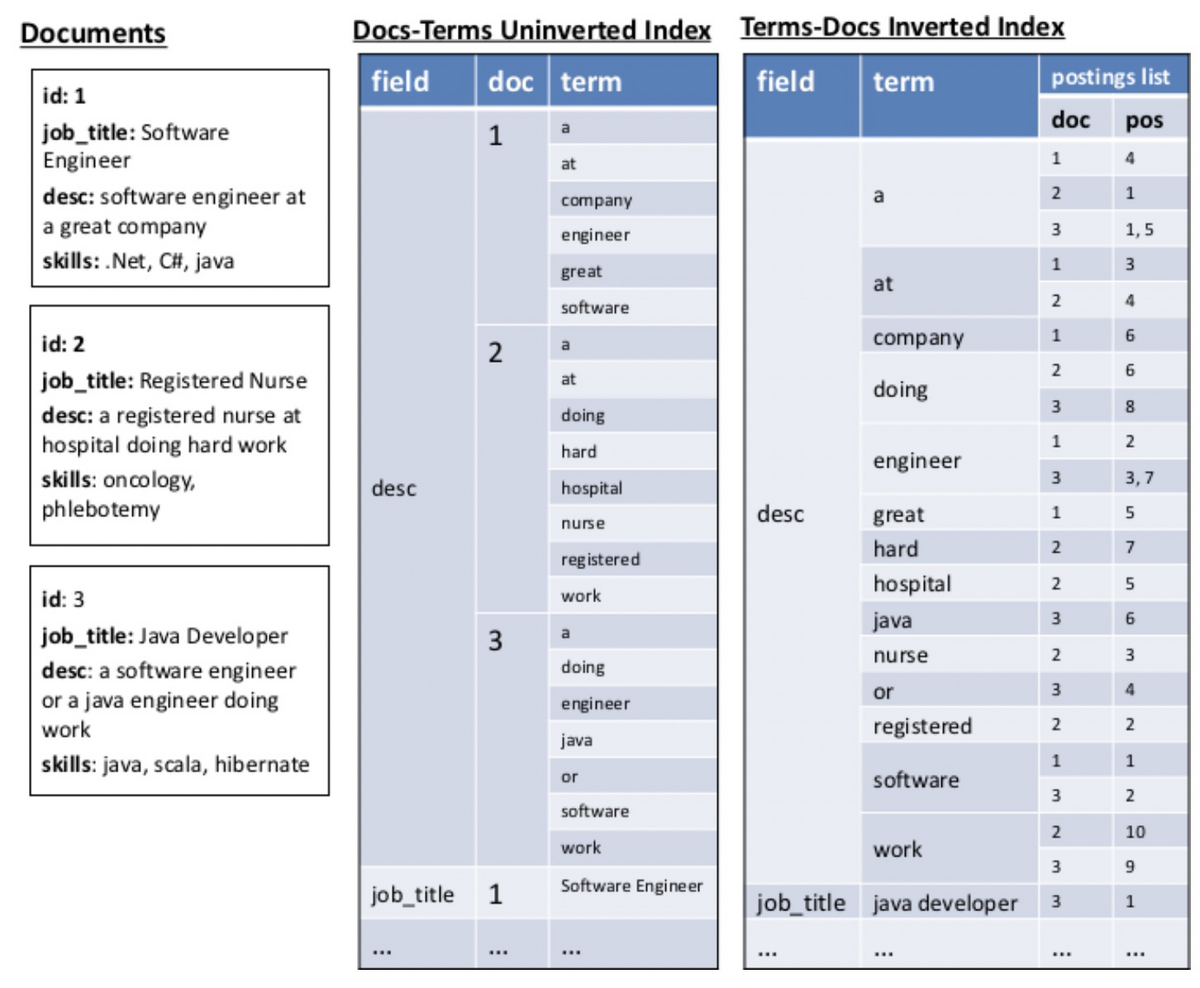
任意のクエリを検索し、転置インデックスを通じて文書の集合を見つける能力があり、さらに、任意の文書の集合を取り出し、それらの文書内の単語を検索する能力もあるとすると、これは、2つの走査(単語→文書→単語)を行うことで、元のクエリを含む文書と一緒に出現する関連語を見つけられることを意味します。以下の図は、このような走査がどのように行われるかを示しています。同じフィールドに対して走査することもできますが、以下では「skill」と「job_title」フィールドに対して走査しています。
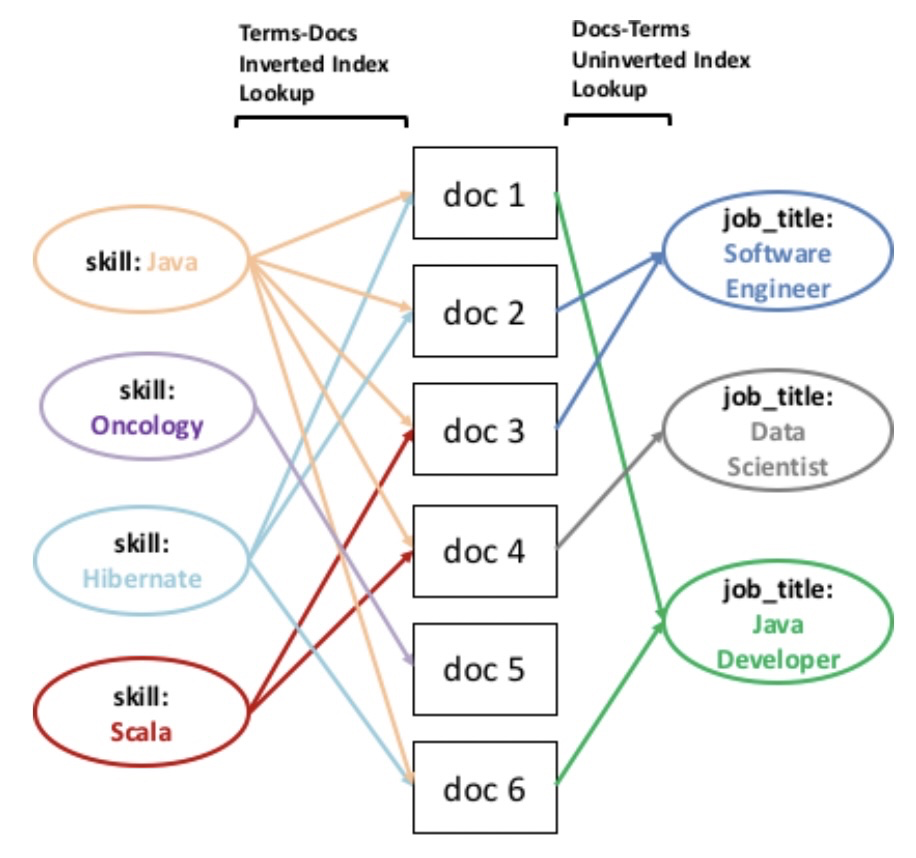
というわけで、グラフを走査できることはわかりましたが、すべてのノード間の関係が等しく重要なわけではないので、エッジに重みを割り当てることが重要になります。それについては本にはほとんど書かれていないので、気になる方は論文[1]を読んでください。
意味的知識グラフを用いた関連語の計算
では、意味的知識グラフを使って関連語を計算してみましょう。自分で実装することもできるでしょうが、本の中ではApache Solrを使って計算していたので、Solrにデータセットをインデックスして実現することにします。
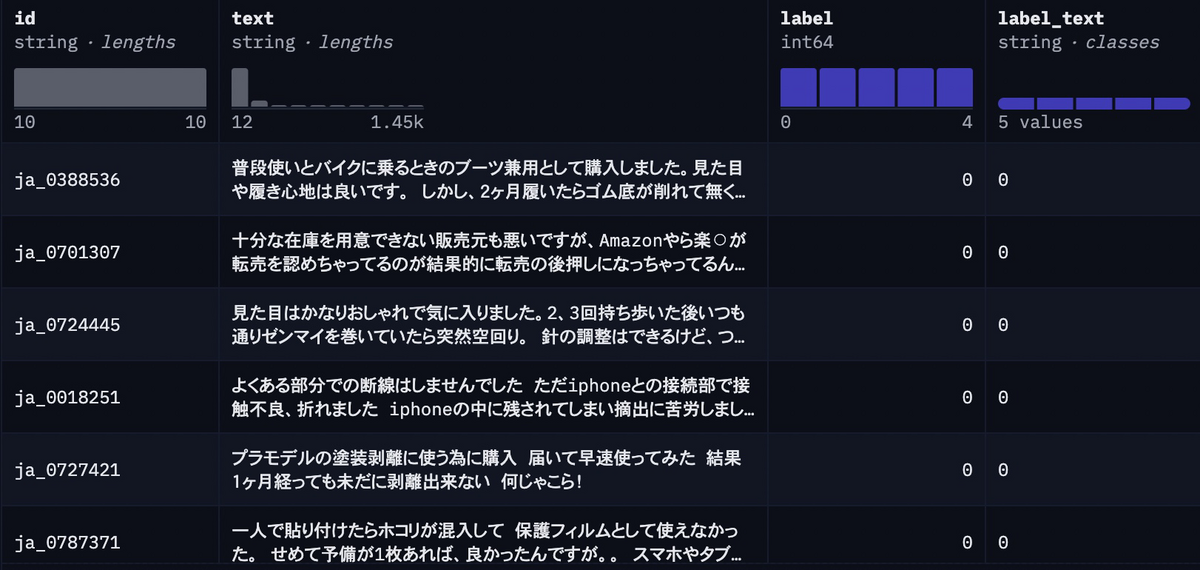
まずデータセットですが、日本語のAmazonレビューデータセット(SetFit/amazon_reviews_multi_ja)を使います。このデータセットには、以下に示すようにID、レビュー本文、ラベルが含まれています。
datasetsライブラリを使ってデータセットをダウンロードしたら、JSON形式で書き出しておきます。
from datasets import load_dataset dataset = load_dataset("SetFit/amazon_reviews_multi_ja") dataset.to_json("example.json")
次に、Apache Solrを立ち上げて、インデックスを作成します。Solrを使う方法はいくつかありますが、今回はDockerを使うことにします。以下のコマンドを実行し、データを登録するためにexampleコアを作成してSolrのコンテナを立ち上げます。
docker run --name solr --rm -p 8983:8983 solr:latest solr-precreate example
Apache Solrを立ち上げたら、スキーマを作成します。以下のコマンドを実行して作成しましょう。
curl --request POST \
--url http://localhost:8983/api/cores/example/schema \
--header 'Content-Type: application/json' \
--data '{
"add-field": [
{"name": "text", "type": "text_ja", "multiValued": false},
{"name": "label", "type": "string"},
{"name": "label_text", "type": "string"}
]
}'
スキーマを作成できたら、データセットをアップロードしてインデックスを作成します。そのために、以下のコマンドを実行します。
curl -H "Content-Type: application/json" \ -X POST \ -d @example.json \ --url 'http://localhost:8983/api/cores/example/update?commit=true'
あとはApache Solrに問い合わせるだけです。以下のコードでは、意味的知識グラフを使って「腰痛」という単語に対する関連語を返すように問い合わせています。なお、本のコードのままだとエラーが発生したため、若干変更しています。
import requests collection = "example" SOLR_URL = "http://localhost:8983/solr" request = { "params": { "qf": "text", "q": "腰痛", # Add this "fore": "{!type=$defType qf=$qf v=$q}", "back": "*:*", "defType": "edismax", "rows": 0, "echoParams": "none", "omitHeader": "true" }, # "query": "腰痛", "facet": { "body": { "type": "terms", "field": "text", "sort": { "relatedness": "desc"}, "mincount": 2, "limit": 8, "facet": { "relatedness": { "type": "func", "func": "relatedness($fore,$back)" } } } } } search_results = requests.post(f"{SOLR_URL}/{collection}/query", json=request).json() for bucket in search_results["facets"]["body"]["buckets"]: print(f'{bucket["relatedness"]["relatedness"]}\t{bucket["val"]}')
結果は以下のとおりです。なんとなく腰痛に関連する単語が取得できているように見えます。
| 単語 | 関連度 |
|---|---|
| 腰痛 | 0.92085 |
| 腰 | 0.52654 |
| 持ち | 0.47165 |
| コルセット | 0.45199 |
| ブレスエア | 0.40135 |
| マットレス | 0.35591 |
| 反発 | 0.31189 |
| 整骨 | 0.30099 |