RAGを作っていると、論文に出てくる表データを読み取って回答してもらう等、表データを扱いたくなってくる場面が出てきます。そんな欲求を頭の片隅に置いておいたところ、Chain-of-Tableと呼ばれるプロンプトの手法を見かけたので試してみました。
本記事の構成は以下のとおりです。
Chain-of-Tableとは
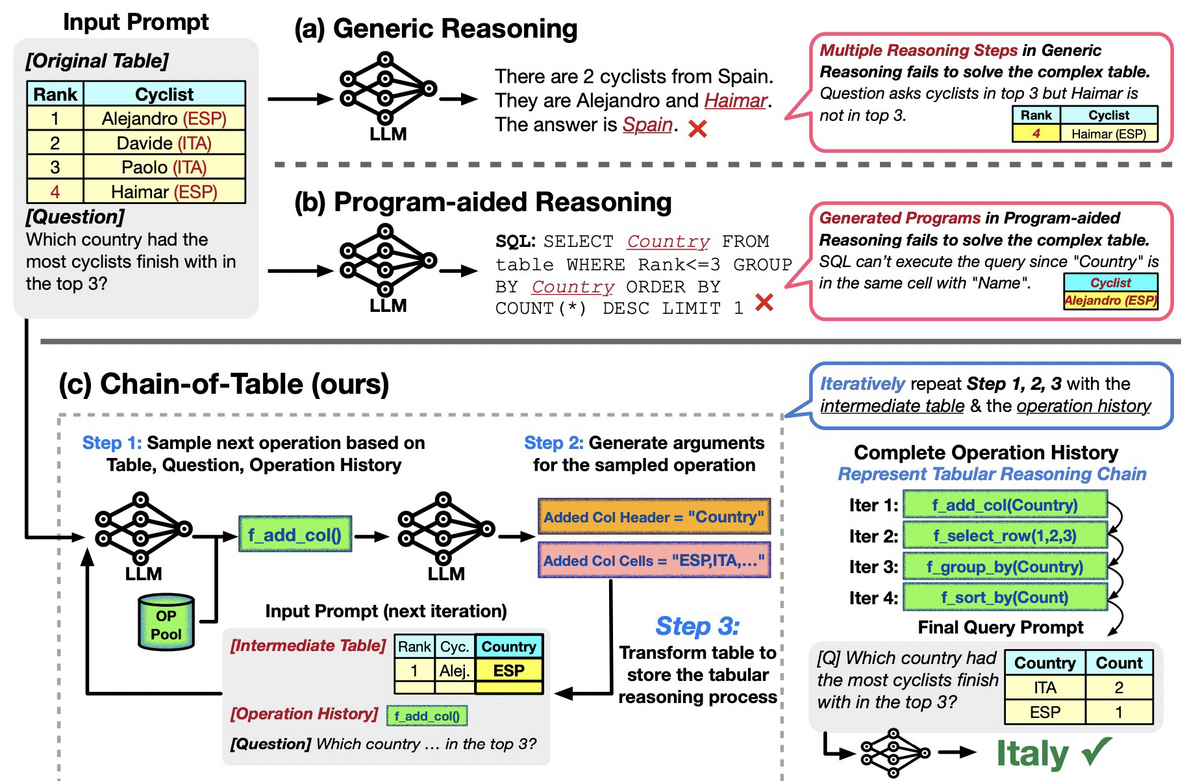
Chain-of-Tableとは、列の追加、行の選択、グループ化、ソート等の操作を段階的にしていくことで、表データを少しずつ理解しクエリに回答する手法です。以下の例では、表データに対して「最も多くのサイクリストがトップ3に入った国は?」という質問をする例です。一般的な推論やProgram-aided Reasoningでは回答に失敗している一方、Chain-of-Tableでは、「列の作成」「行の選択」「グループ化」「ソート」を行うことで、正しい回答である「Italy」を生成できています。
以下にPython風の擬似コードを載せました。論文にはちゃんと擬似コードが載っているので、そちらを見るのもよいでしょう。基本的には、1. 表と質問と演算列から次の演算fを生成、2. fに対する引数argsを生成、3. 表に対して演算を実行して更新、を繰り返すだけです。終了タグが生成された場合はループから抜け、回答を生成します。
def chain_of_table(T, Q): """Chain-of-Tableアルゴリズム Args: T : 表 Q : 質問 Returns: A: 質問に対して生成した回答 """ # 演算列を[B]とϕで初期化 # ここで、[B]は開始タグを表し、ϕは引数を必要としないことを表す chain = [([B], ϕ)] while True: # 表と質問と演算列から次の演算fを生成 f = DynamicPlan(T, Q, chain) # fに対する引数argsを生成 args = GenerateArgs(T, Q, f) # 表に対して演算を実行して更新 T = f(T, args) # 演算を追跡 chain.append((f, args)) # 終了タグ[E]が生成されるまで表を繰り返し更新 if f == [E]: break # 回答を生成 A = Query(T, Q) return A
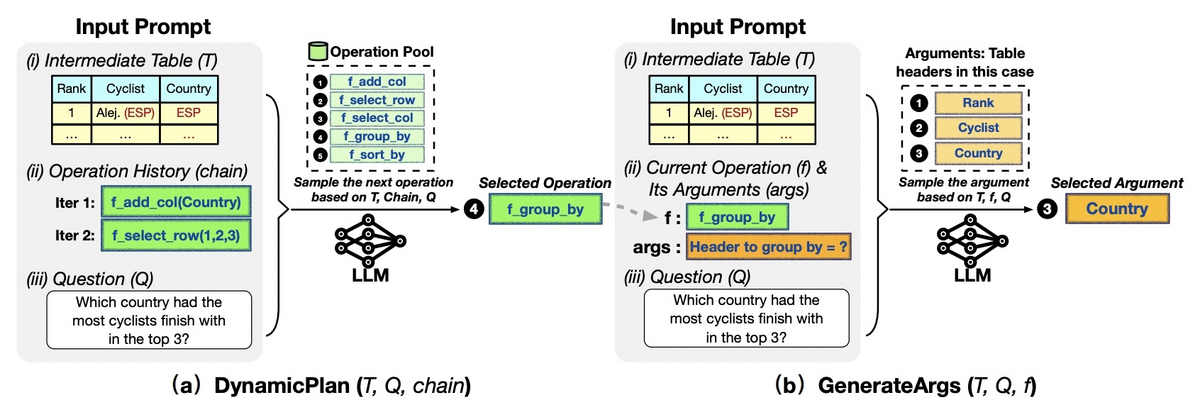
DynamicPlanとGenerateArgsの様子を以下に示します。DynamicPlanでは表と質問と演算列から次の演算を選択します。以下の例では、過去の演算と中間テーブルを考慮して、f_group_byを選択しています。GenerateArgsでは、表と質問と選択した演算fから、fに対する引数を選択します。以下の例ではCountryを選択しています。したがって、このあとはCountryでのグループ化が実行されることになります。
プロンプトに表を与える仕組み上、巨大な表では試せないので、小さな表で試してみましょう。
Chain-of-Tableの実装
LlamaIndexが実装を提供していたので、そちらをありがたく使わせていただきましょう。まずは関連パッケージをインストールします。ちなみに、Pandasはデータセットを読み込むだけでなく、表に対する演算を実行するためにも使われています。
pip install -q llama-index pandas # arize-phoenix
次にデータセットとしてWikiTableQuestionsをダウンロードします。このデータセットは、Wikipediaから取得したさまざまな半構造化テーブルに対する質問応答のデータセットです。
wget "https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip" -O data.zip unzip data.zip
映画の受賞者に関するデータセットを読み込んで表示してみましょう。
import pandas as pd df = pd.read_csv("WikiTableQuestions/csv/200-csv/11.csv") df.head(3)
| index | Award | Category | Nominee | Result |
|---|---|---|---|---|
| 0 | Academy Awards, 1972 | Best Picture | Phillip D'Antoni | Won |
| 1 | Academy Awards, 1972 | Best Director | William Friedkin | Won |
| 2 | Academy Awards, 1972 | Best Actor | Gene Hackman | Won |
データセットを用意できたので、Chain-of-Tableを用意します。Chain-of-TableはLlamaHub上でLlamaPackとして公開されているので、まずはダウンロードします。
from llama_index.llama_pack import download_llama_pack download_llama_pack( "ChainOfTablePack", "./chain_of_table_pack", skip_load=True, )
ダウンロードしたら、インポートして使えるので、以下のようにします。
from chain_of_table_pack.base import ChainOfTableQueryEngine, serialize_table from llama_index.llms import OpenAI llm = OpenAI(model="gpt-4-1106-preview") query_engine = ChainOfTableQueryEngine(df, llm=llm, verbose=True)
あとは質問するだけです。以下では「Who won best Director in the 1972 Academy Awards?(1972年のアカデミー賞で監督賞を受賞したのは誰?)」という質問をしています。
response = query_engine.query("Who won best Director in the 1972 Academy Awards?") str(response.response)
結果は以下のとおりです。正しい回答です。
assistant: William Friedkin.
では次に、日本語で質問しています。実は過去に研究開発でSpiderというデータセットを用いたセマンティックパージングにわずかに関わっていたことがあり、その時にクエリ中の単語と列名のマッチングが重要であるという知見を得ていました。GPT-4は多言語に対応できるので、そのへんの問題はある程度解決できるでしょうが、試してみましょう。
response = query_engine.query("1972年のアカデミー賞で監督賞を受賞したのは誰?") str(response.response)
結果は以下のとおりです。日本語化されていますが、正しい回答です。
assistant: ウィリアム・フリードキンです。
これだけだと単に行を選択して、そこから回答を抽出しているだけなので、あまりありがたみがないのですが、ノートブックにはより複雑な例もあります。ただ、自分で複雑なクエリを試したところ、引数の抽出でエラーが頻発するという結果になりました。実装的に、正規表現を使って引数を抽出しているのですが、その部分は改善の余地がありそうです。