多言語のテキスト埋め込み用のモデルであるMultilingual-E5-largeの性能を日本語のデータセットで評価してみました。
E5とは
E5とはEmbEddings from bidirEctional Encoder rEpresentationsの略で、テキストの埋め込み用のモデルです[1]。Web上から収集した大規模なテキストペアのデータセット(CCPairs)で対照学習したあと、NLIやMS Marcoなどの高品質なデータセットで学習しています。情報検索のベンチマークであるBEIR[2]や埋め込みのベンチマークであるMTEB[3]で評価されており、MTEBではOpenAIのtext-embedding-ada-002を上回る性能が報告されています。

CCPairsはWeb上から収集されており、具体的にはRedditの(投稿、コメント)、StackExchangeの(質問、いいねされた回答)、Wikipediaの(エンティティ名+セクションタイトル、パッセージ)、科学技術系論文の(タイトル、アブストラクト)、CommonCrawlの(タイトル、パッセージ)です。集めたデータはフィルタリングして270M件まで減らしたあと、対照学習に使い、その後NLI、MS Marco、NQを使って学習しています。なお、学習時にquery:とpassage:というプレフィックスを付けているので、予測時にも付けることが推奨されています。

E5のモデルはHuggingFace Hubに公開されており、Transformersを通じて以下のように使うことができます。
import torch.nn.functional as F from torch import Tensor from transformers import AutoTokenizer, AutoModel def average_pool(last_hidden_states: Tensor, attention_mask: Tensor) -> Tensor: last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0) return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None] input_texts = [ 'query: 今日の天気は?', 'query: 南瓜的家常做法' ] tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-small') model = AutoModel.from_pretrained('intfloat/multilingual-e5-small') batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt') outputs = model(**batch_dict) embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
評価
E5には多言語用のモデルとして以下の2つが公開されています。小さなモデルは多言語のMiniLM、大きなモデルはxlm-roberta-largeをもとにしています。また、学習データも英語版とは異なっており、多言語のデータが含まれています。今回はこれらのモデルの性能を日本語のデータセットであるJSTS[4]を使ってOpenAIのtext-embedding-ada-002と比較してみます。
JSTSは、日本語の文ペアの意味がどのくらい近いかを測定するためのデータセットです。JSTSは、日本語の画像キャプションデータセットであるYJ Captionsから抽出された文とクラウドワーカーが作成した文に類似度スコアを付与することで作成されています。正解の類似度は、0〜5までの間の値が付与されており、0に近いほど文ペアの意味が異なり、5に近いほど文ペアの意味が似ていることを表しています。以下にデータの例を示します。
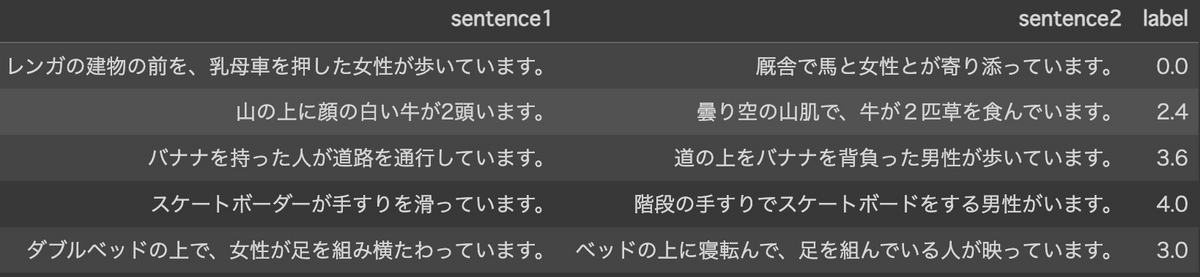
評価結果は以下のとおりです。E5の小さなモデルはtext-embedding-ada-002と同じくらいの性能であり、大きなモデルは上回る性能となりました。扱える系列長はOpenAIのモデル(8191)と比べてだいぶ短い(512)ですが、日本語データに対しても良い性能を発揮してくれそうです。
| モデル | スコア(Pearson/Spearman) |
|---|---|
text-embedding-ada-002 |
0.8372/0.7902 |
multilingual-e5-small |
0.8344/0.7892 |
multilingual-e5-large |
0.8620/0.8185 |