ChatGPTやGPT-4をはじめとする大規模言語モデルの能力が向上し、多くの注目を集めています。とくにRAG(Retrieval Augmented Generation)と呼ばれる手法を使って、手元のデータを生成時に活用する手法がよく使われていますが、その性能を改善する方法は様々あります。その中でも、この記事ではRAG内部の検索性能を改善するためのクエリ変換に着目し、HyDEと呼ばれる手法の効果を日本語の検索用データセットを使って検証した結果を示します。
記事の構成は以下のとおりです。
HyDEとは
HyDE(Hypothetical Document Embeddings:仮の文書の埋め込み)は、入力されたクエリに対して仮の文書を生成し、その文書を埋め込み、検索に使用する手法です[1]。典型的な文書検索では、ユーザーが入力したクエリと文書の類似度を計算することが多いですが、クエリと文書が必ずしも類似しているとは限りません。そのため、生成モデルを使って回答のような文書(Hypothetical Document)を生成し、その文書と検索エンジンに格納された文書の類似度を計算してしまおうという考え方になります。
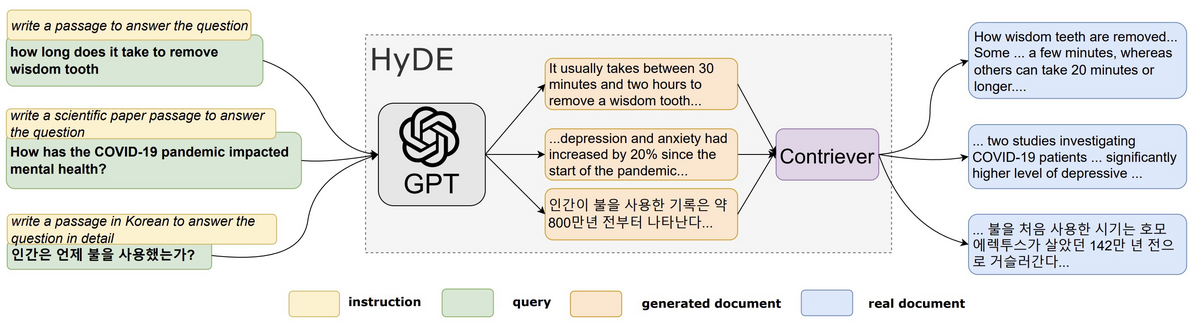
HyDEによるクエリ変換の例として、「国民年金の免除申請をしたいのですが、申請に必要な持ち物は何を持っていけば良いですか?」というクエリを変換した例を以下に示します。内容が正しいとは限りませんが、回答のような文書が生成されていることがわかります。元のクエリの代わりに、この文書をクエリとして使うことになります。
国民年金の免除申請をする際には、いくつかの持ち物が必要です。まず、申請書が必要ですので、市役所や年金事務所で入手するか、インターネットでダウンロードして印刷してください。また、申請者本人の本人確認書類も必要です。これには、運転免許証やパスポート、健康保険証などがあります。さらに、収入証明書も必要ですので、給与明細や年金受給証明書などを用意してください。また、免除申請の理由を証明するために、医療証明書や障害者手帳などの医療関係の書類も必要です。これらの持ち物を整理して、申請時に提出することで、スムーズに免除申請をすることができます。申請に必要な持ち物は、市役所や年金事務所のウェブサイトなどで詳細を確認してください。
まとめると、HyDEでは以下の手順で検索をすることになります。
実験設定
本記事では、日本語でのキーワード検索とベクトル検索に対して、HyDEによるクエリ変換を適用し、その結果を評価します。構成としては、論文の図と同じものになります。以下では、クエリ変換用のモデル、検索用のモデル、評価用データセットおよび評価指標について説明します。
論文ではクエリ変換用のモデルとしてGPT-3(text-davinci-003)を使用していますが、今回はGPT-3.5 Turboを使用しました。temperatureには0を設定しています。
論文では検索用にContrieverを利用していますが、今回は以下の2つを用意しました。それぞれキーワード検索とベクトル検索に対応しています。どちらもLangChainの実装を使用しています[2][3]。
- BM25
- OpenAIの
text-embedding-ada-002
評価用のデータセットとしては、以前に書いた「Cohereの多言語用の埋め込みモデルを日本語で評価してみる」でも使った尼崎市のQAデータ[4]を使用します。評価については上位10件のヒット率とMRR(Hit Rate@10、MRR@10)ですることにします。
実験結果
評価結果は以下のとおりです。キーワード検索の場合は、HyDEを適用することで性能が低下する一方、ベクトル検索の場合はHyDEを使うことで性能が向上するという結果になりました。変換前のクエリと変換後のクエリに対して、BLEUを使って正解文書と不正解文書に対する類似度を計算したところ、HyDEによる変換後のクエリは正解・不正解文書どちらともBLEUスコアが上昇していました。不正解文書との単語の重なりが多くなったために性能が低下した可能性があります。
| モデル | Hit Rate@10 | MRR@10 |
|---|---|---|
| BM25 | 0.5918 | 0.3955 |
| BM25 + HyDE | 0.5332 | 0.3451 |
text-embedding-ada-002 |
0.8355 | 0.6436 |
text-embedding-ada-002 + HyDE |
0.8712 | 0.6546 |
2023/11/26追記:BM25の設定を見直し。傾向には変化なし。
実装の詳細
実装には、LangChainのRePhraseQueryRetriever[5]を使うことができます。この検索器は、クエリが与えられたら、LLMを使ってクエリを言い換えます。そして、ベースとなる検索器に対して言い換えたクエリを使って文書を取得します。
たとえば、以下のコードの場合、LLMとしてOpenAIのチャットモデルを、ベースとなる検索器としてBM25Retrieverを渡してRePhraseQueryRetrieverを作成しています。デフォルトの言い換え用プロンプトも用意されているので、プロンプトを渡さずに使うこともできます。
from langchain.chat_models import ChatOpenAI from langchain.retrievers.bm25 import BM25Retriever from langchain.retrievers.re_phraser import RePhraseQueryRetriever llm = ChatOpenAI(temperature=0) base_retriever = BM25Retriever.from_documents(...) retriever = RePhraseQueryRetriever.from_llm( retriever=base_retriever, llm=llm )
HyDEを使う場合は、HyDE用のプロンプトを定義して渡すだけです。こうすることで、生成した仮の文書を使って検索できるようになります。なお、今回は論文で使っていたプロンプトと同様のプロンプトを使用していますが、対象としているドメインに応じて書き換えるとよいでしょう(論文にいくつかの例がある)。ちなみに、LangChain TemplatesにもHyDEのテンプレート[6]が用意されているので、そちらで試すこともできます。
from langchain.prompts.prompt import PromptTemplate hyde_template = """Please write a passage in Japanese to answer the question in detail. Question: {question} Passage:""" hyde_prompt = PromptTemplate.from_template(hyde_template) retriever = RePhraseQueryRetriever.from_llm( retriever=base_retriever, llm=llm, prompt=hyde_prompt )
なお、実験では変換後のクエリを使いまわしたかったため、RePhraseQueryRetrieverの外側でクエリの変換をしています。今回は使っていませんが、LangChainにはHypotheticalDocumentEmbedderというチェインも用意されているため、こちらを使って実現することもできると思います。