検索性能を改善するハイブリッド検索で使えるランク融合アルゴリズム
Risk-Reward Trade-offs in Rank Fusionを読んでいて、検索システムの結果を統合するために使える教師なしのランク融合アルゴリズムについて書きたくなったのでまとめました。最近では、RAGの性能を改善するためにハイブリッド検索が使われることがありますが、その内部で各検索システムの結果を統合するために使うことができます。実際に計算する方法と合わせて紹介します。
記事の構成は以下のとおりです。最初に、検索の文脈からランク融合アルゴリズムについて例を交えて紹介した後、実際に計算する方法を紹介します。
アルゴリズム
本記事で紹介するアルゴリズムはスコアベースと順位ベースの2つに分けられます。スコアベースのアルゴリズムは、検索システムが出力するスコアを利用するのが特徴的で、代表的なアルゴリズムとして CombSUM や CombMNZ が挙げられます。一方、順位ベースのアルゴリズムは、検索結果の順位を利用するのが特徴的で、代表的なアルゴリズムとして Borda や RRF が挙げられます。以下では、これらのアルゴリズムについて例を用いて説明します。
CombSUM
CombSUM は Fox らにより提案されたシンプルなアルゴリズムです[2]。ちなみに、論文では次の節で説明する CombMNZ を含む Comb 系の指標(CombMAX、CombMINなど)をいくつか提案しています。CombSUM でのスコアは、システム における文書
のスコアを
で表すと、以下の式で計算できます。
理解を深めるために以下の表に具体例を挙げます。この表では、各文書に対してシステムごとのスコアが記載されており、それらの和をとり最終的なスコアとしています。最終的なスコアをもとに決まった順位は d5 -> d4 -> d3 -> d1 -> d2 となりました。
| 文書 | システム1のスコア | システム2のスコア | 最終的なスコア | 順位 |
|---|---|---|---|---|
| d1 | 1.34 | 0.85 | 2.19 | 4 |
| d2 | 1.43 | 0.71 | 2.14 | 5 |
| d3 | 1.93 | 1.00 | 2.93 | 3 |
| d4 | 2.12 | 1.02 | 3.14 | 2 |
| d5 | 2.34 | 1.23 | 3.57 | 1 |
スコアを足して計算するという仕組み上、スコアが取りうる範囲は重要です。たとえば、あるシステムのスコアの範囲がほかと比べて広い場合、最終的なスコアはそのシステムの影響を大きく受けてしまいます。以下にその例を示します。この例の場合、順位はシステム3の影響を大きく受けていることがわかります。したがって、各システムのスコアを正規化してから最終的なスコアを計算したほうがよいでしょう。
| 文書 | システム1のスコア | システム2のスコア | システム3のスコア | 最終的なスコア | 順位 |
|---|---|---|---|---|---|
| d1 | 1.34 | 0.85 | 18756 | 18758.19 | 2 |
| d2 | 1.43 | 0.71 | 2342 | 2344.14 | 4 |
| d3 | 1.93 | 1.00 | 123 | 125.93 | 5 |
| d4 | 2.12 | 1.02 | 19685 | 19688.14 | 1 |
| d5 | 2.34 | 1.23 | 2341 | 2344.57 | 3 |
次に、CombSUM によく似た CombMNZ を紹介します。
CombMNZ
CombSUM も Fox らにより提案されたアルゴリズムで、CombSUM の派生形とみなすことができます[2]。CombMNZ でのスコアは、システム における文書
のスコアを
、文書
を検索したシステム数を
で表すと、以下の式で計算できます。気持ち的には、複数のシステムで検索された文書をより重視したいということになります。
次にBordaを紹介します。
Borda
Borda は順位ベースのシンプルなアルゴリズムです。かなり昔から存在するアルゴリズムですが、18世紀のフランスの数学者であるBordaにちなんで命名されました[3]。各システム内での順位に基づいて文書にスコアを割り当て、それらのスコアを使って最終的なスコアを計算します。 を検索された文書数、
をシステム
における文書
の順位とすると、以下の式で計算できます。
理解を深めるために以下の表に具体例を挙げます。この表では、CombSUM の表に記載したスコアから各システムごとに文書の順位を計算し、それらの値をもとにスコアを計算しています。最終的なスコアから求められる順位は d5 -> d4 -> d3 -> d1 == d2 となりました。
| 文書 | システム1のスコア | システム2のスコア | 最終的なスコア | 順位 |
|---|---|---|---|---|
| d1 | (5 - 5) = 0 | (5 - 4) = 1 | 1 | 4 |
| d2 | (5 - 4) = 1 | (5 - 5) = 0 | 1 | 4 |
| d3 | (5 - 3) = 2 | (5 - 3) = 2 | 4 | 3 |
| d4 | (5 - 2) = 3 | (5 - 2) = 3 | 6 | 2 |
| d5 | (5 - 1) = 4 | (5 - 1) = 4 | 8 | 1 |
Bordaは式にバリエーションがあるので、気になる方は調べてみてください。次に、ハイブリッド検索でもよく使われているRRFについて紹介します。
RRF
RRF(Reciprocal Rank Fusion)も Borda と同じく順位ベースのアルゴリズムです[4]。RRFでは各システムでの文書の逆順位に基づいて文書ごとにスコアを計算し、それらのスコアを使って最終的なスコアを計算します。逆順位を使っているのは、より上位に検索された文書により大きな重みを与えるためです。システム における文書
の順位
とハイパーパラメーターである
から、以下の式で計算できます。
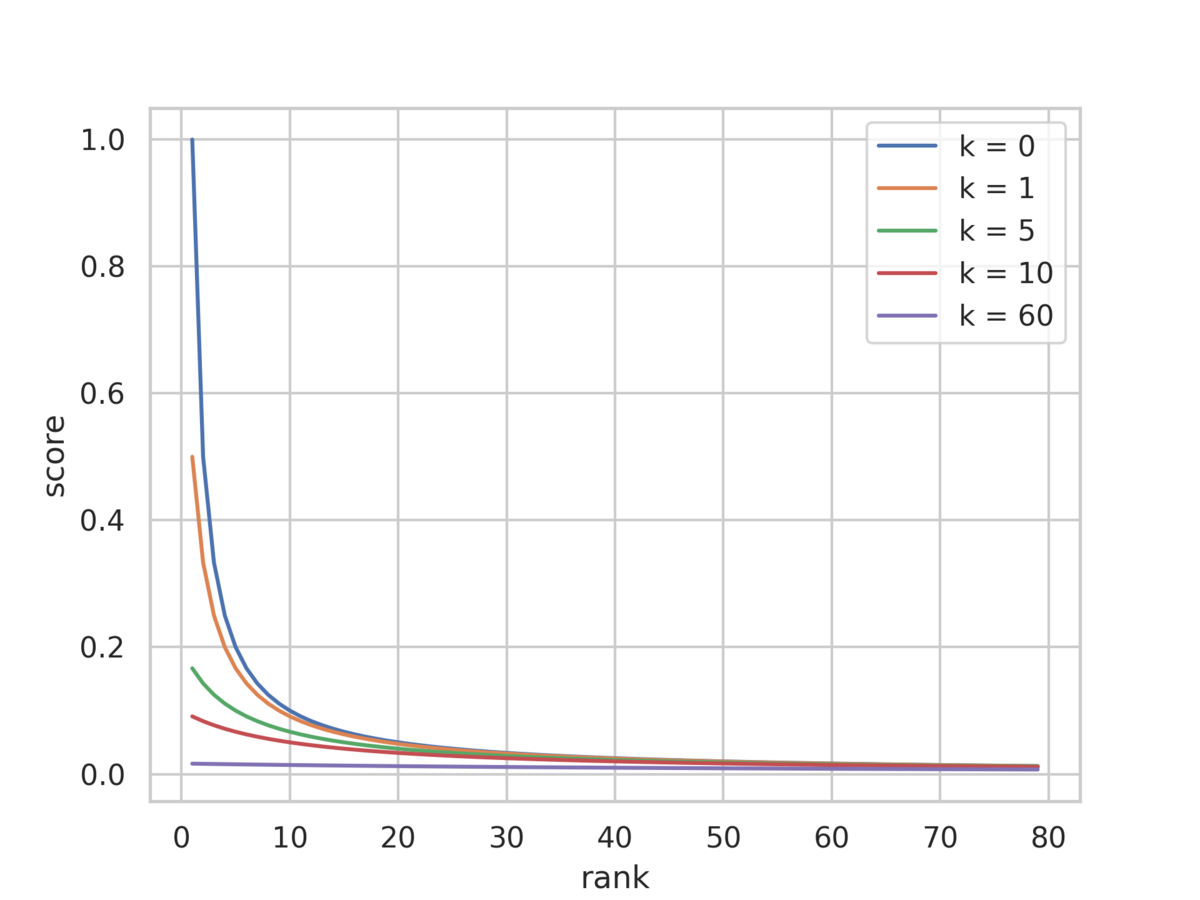
ハイパーパラメーター のデフォルト値としては60がよく使われています。この値は、文書の順位が最終的な順位に与える影響を決めており、値が大きいほど下位の文書の影響力が大きくなります。以下の図では、
と順位を変えたときのスコアの変化を示しています。
を大きくすることで、上位と下位の文書間でのスコアの差が縮まっていることを確認できます。
RRFも実際に計算して理解を深めてみましょう。この表では、CombSUM の表から計算できる各システムごとの文書の順位をもとにスコアを計算しています。ここでは、話を簡単にするために としています。最終的なスコアからは d5 -> d4 -> d3 -> d1 == d2 という順位が得られます。
| 文書 | システム1のスコア | システム2のスコア | 最終的なスコア | 順位 |
|---|---|---|---|---|
| d1 | 1/5 | 1/4 | 0.450 | 4 |
| d2 | 1/4 | 1/5 | 0.450 | 4 |
| d3 | 1/3 | 1/3 | 0.666 | 3 |
| d4 | 1/2 | 1/2 | 1.000 | 2 |
| d5 | 1/1 | 1/1 | 2.000 | 1 |
以上でアルゴリズムの紹介は終わります。ここで紹介したアルゴリズム以外にも、RRFの拡張版であるISRやlogISR、RBCなど多数存在するため、興味があれば調べてみてください。では、次に実際に計算する方法について紹介します。
実際に計算したいときは?
LangChainのEnsembleRetrieverや、Weaviateのようなハイブリッド検索の機能を組み込んだサービスを使うとランク融合のアルゴリズムを利用できますが、このようなアルゴリズムは多数あるので、組み込みのアルゴリズム以外を試したり、ハイパーパラメーターを変えたときの結果を確認したくなるときがあります。とはいえ、自分で検索器を実装するのは面倒ですし、評価するたびに検索器を実行していたら時間もお金もかかります。
そこで、個人的には ranx というPython製のランキング評価用ライブラリを使っています。ranx を使うと、たとえばキーワード検索とベクトル検索を一度だけしておいて、ランク融合アルゴリズムだけ変えたときの性能を測定できます。実装量の少なさや、検索器を何度も実行する必要がない点を気に入っています。また、ハイパーパラメーターの最適化機能もサポートしており、たとえば RRF における k をチューニングしたときの性能を測定することもできます。
計算方法の詳細は「ranxを使って検索システムのオフライン評価をする」という記事で解説しているのでそちらを参照していただければと思います。簡単に説明すると、各システムの結果(Runと呼ばれる)とランク融合アルゴリズム、最適化したい指標をoptimize_fusion関数に渡すと最適なハイパーパラメーターを推定してくれます。そして、fuse関数を使うことで、統合結果を表すRunを返してくれる仕組みになっています。あとはこのRunを使って指標を計算するだけです。
from ranx import fuse, optimize_fusion best_params = optimize_fusion( qrels=train_qrels, runs=[train_run_1, train_run_2, train_run_3], method="rrf", metric="ndcg@100", # The metric to maximize ) combined_test_run = fuse( runs=[test_run_1, test_run_2, test_run_3], method="rrf", params=best_params, )
測定できる指標にはヒット率や再現率、MRR、NDCGなど有名どころを一通り備えており、ランク融合アルゴリズムも20以上備えています。詳細については、以下の公式ドキュメントを参照してください。