RAG(Retrieval Augmented Generation)は大規模言語モデル(LLM)の性能を改善するための手法の1つであり、質問に対する回答を生成する際に、外部知識源から情報を取り込みます。 これにより、LLM 自体で学習できる情報量に制限されることなく、より正確で詳細な回答を生成することができます。
よく使われているRAGでは、外部知識源として検索エンジンにテキストをインデックスしておき、質問に関連するテキストをベクトル検索や全文検索を用いて取得します。しかし、構造化データを扱うことには苦労するため、質問によっては回答が不十分、あるいはまったく回答できないことに繋がります。
これらの問題を克服するために、ナレッジグラフを用いたRAGが構築されることがあります。ナレッジグラフでは、エンティティとその間の関係がグラフ構造で表現されており、単純な検索を用いた場合には回答できないような複雑な質問にも対応できます。
本記事では、ナレッジグラフを用いた RAG モデルの改善について紹介します。 具体的には、以下の内容について解説します。
- Neo4jのセットアップ
- ナレッジグラフの構築
- ナレッジグラフを用いたRAGの構築
Neo4jのセットアップ
今回は、グラフデータベースとしてNeo4jを使うので、そのインスタンスをセットアップする必要があります。最も簡単な方法は、クラウド上でNeo4jのインスタンスを提供しているNeo4j Auraの無料プランを使うことです。今回はこちらのプランを使いますが、Neo4j Desktopをセットアップすればローカルにインスタンスを立てることもできます。
Neo4j Auraの無料インスタンスを作成したら、URLやユーザー名、パスワード、データベース名を取得し、以下の定数に設定します。
NEO4J_URI = "" NEO4J_USERNAME = "neo4j" NEO4J_PASSWORD = "" NEO4J_DATABASE = "neo4j"
Neo4jとのやり取りは、LangChainのNeo4jGraph経由で行うため、取得した情報を与えてインスタンスを作成します。
from langchain_community.graphs import Neo4jGraph kg = Neo4jGraph( url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE )
ナレッジグラフの構築
次に、ナレッジグラフを定義しましょう。今回は実験のために、以下に示す簡単なグラフを定義します。このグラフは会社の組織構造を表しており、部門が本部に所属するという関係があります。また、部門は部門名、略称、部門コードという3つのプロパティを持ちます。

ナレッジグラフを定義したら、データを取り込んでグラフを構築します。今回は簡単のために3つの部門と2つの本部、そしてその間の関係を以下に示すように定義しています。
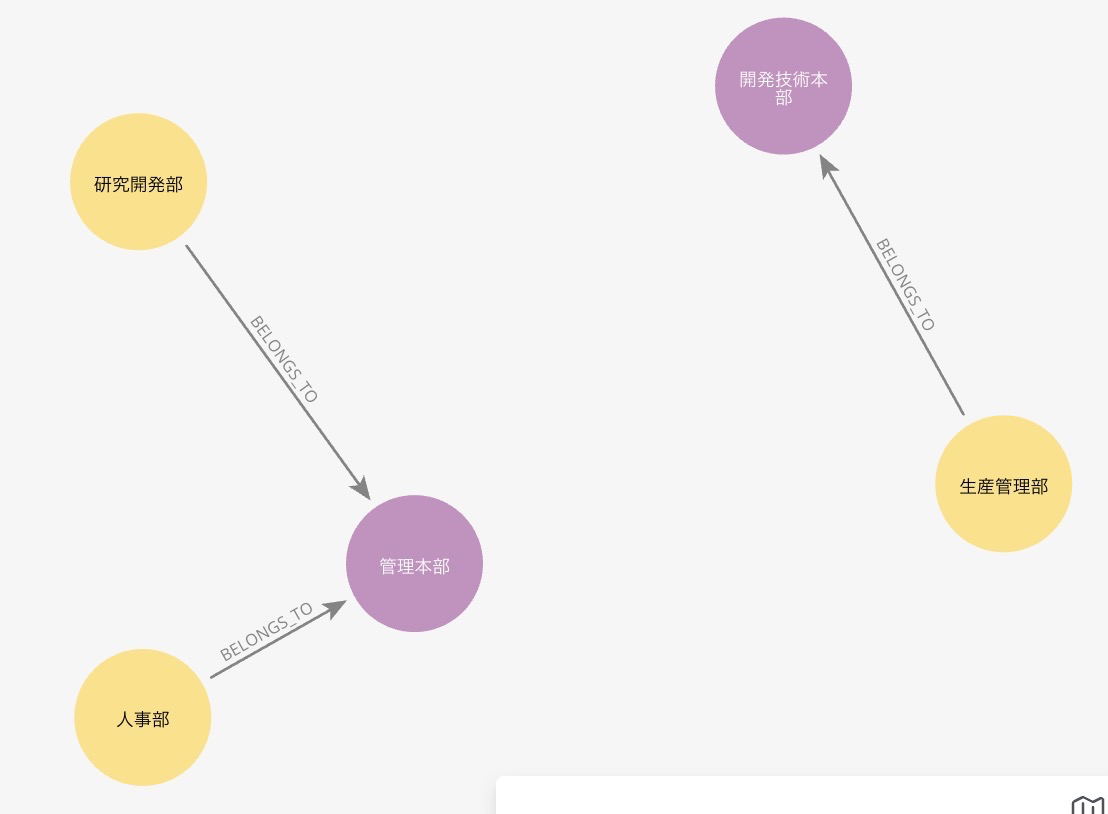
データが格納されているか確かめるために、グラフに問い合わせてみましょう。以下のクエリではデータの件数を問い合わせています。
cypher = """ MATCH (n) RETURN count(n) """ kg.query(cypher)
結果は以下のとおりです。結果を見ると、取り込んだ5つのノードの件数が表示されていることがわかります。
[{'count(n)': 5}]
ナレッジグラフを用いたRAGの構築
では、ナレッジグラフを用いたRAGを構築しましょう。まずはプロンプトを定義します。以下のプロンプトでは、質問をCypherというクエリ言語に変換することを指示しています。プロンプトには、タスクの指示以外に、定義したナレッジグラフのスキーマとFew-shotの例を与えるようにしています。
from langchain.prompts.prompt import PromptTemplate CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database. Instructions: Use only the provided relationship types and properties in the schema. Do not use any other relationship types or properties that are not provided. Schema: {schema} Note: Do not include any explanations or apologies in your responses. Do not respond to any questions that might ask anything else than for you to construct a Cypher statement. Do not include any text except the generated Cypher statement. Examples: Here are a few examples of generated Cypher statements for particular questions: # 研究開発部の略称は? MATCH (dep: 部門) WHERE dep.名前 = '研究開発部' RETURN dep.略称 The question is: {question}""" CYPHER_GENERATION_PROMPT = PromptTemplate( input_variables=["schema", "question"], template=CYPHER_GENERATION_TEMPLATE )
プロンプトを定義したら、LangChainのGraphCypherQAChainを使ってチェインを用意します。このチェインでは、与えられた質問に基づいたCypherクエリの生成、ナレッジグラフへの問い合わせ、問い合わせ結果を用いた回答の生成をしてくれます。
from langchain_openai import ChatOpenAI from langchain.chains import GraphCypherQAChain cypherChain = GraphCypherQAChain.from_llm( ChatOpenAI(), graph=kg, verbose=True, cypher_prompt=CYPHER_GENERATION_PROMPT, )
では、問い合わせてみましょう。まずは簡単な質問からです。この質問であればナレッジグラフを使う必要もありませんが、正しいCypherのクエリと回答を生成できていることがわかります。

次に、管理本部に属する部門を列挙させてみましょう。このような質問は、一般的な検索エンジンでは、検索結果として取得する文書数を固定することが多いため、それ以上の数の部門が存在する場合に答えられなくなるという問題があります。結果を見ると、正しく回答できていることがわかります。

さらに難しいクエリも試してみましょう。以下のクエリでは、属している本部を明らかにしたあと、その本部に属する部門を検索するという多段階の推論が必要になります。以下の結果を見ると、通常の検索エンジンを用いたRAGでは回答するのが難しい質問にも回答できていることがわかります。

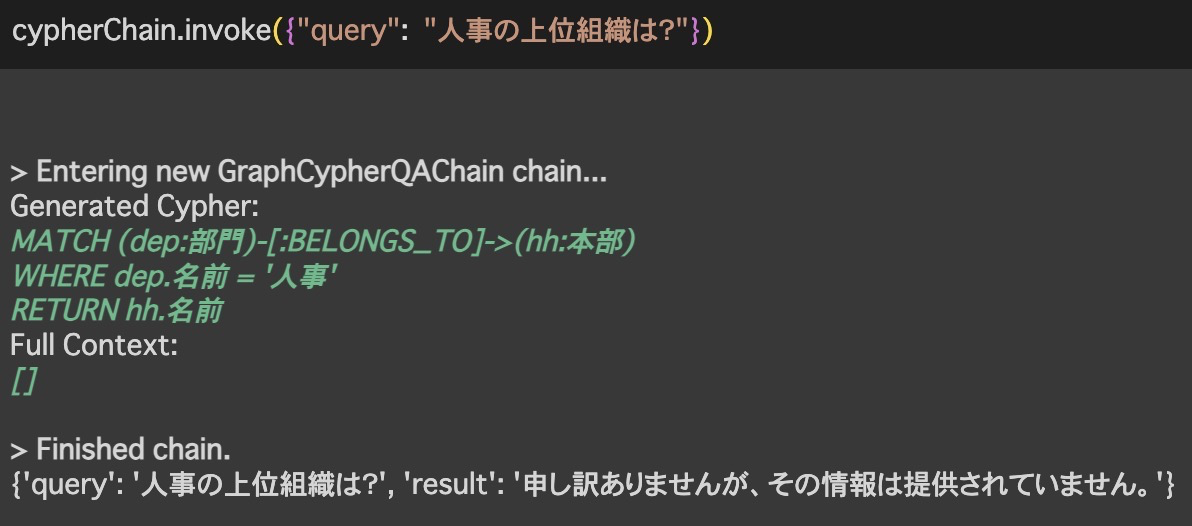
定義したプロンプト的に、略称と正式な部門名を区別できないと考えられるため、以下に失敗するケースを示します。このケースでは、質問文に人事部の略称である「人事」を含めた質問をしていますが、生成されたクエリを見ると、想定通り正式名称と略称の区別がついておらず、検索に失敗していることがわかります。この問題を解決するためには、必要な情報をプロンプトに追加で与える必要があります。
ほかにも注意するべき点として、性能を向上させるためのFew-shotデータの選択方法やベクトル検索などとの使い分け(ルーティング)がありますが、ナレッジグラフをうまく使えば、RAGの性能を改善できそうなことがわかりました。