本記事では、LangChain Templates[1]を利用し、RAGを簡単かつ迅速に構築する方法を紹介します。LangChainはLLMを使ったアプリケーションを実装するためのツールですが、LangChain Templatesを活用することで、煩雑なプロセスを大幅に簡略化できます。本記事では、LangChain Templatesの基本から、実際のRAGの実装までをステップバイステップでガイドします。
以降では、以下の内容について説明します。
LangChain Templatesとは
LangChain Templatesは、LangChainを使ったLLMアプリケーションを簡単に構築するためのテンプレート集です。これらのテンプレートには、LLMアプリケーションで頻繁に使われるアーキテクチャが含まれており、たとえばRAGやOpenAI Functionsを使った情報抽出、エージェントなどをコマンド1つで作成し、ブラウザからその動作を確認できます。以下は典型的なテンプレートの例です。
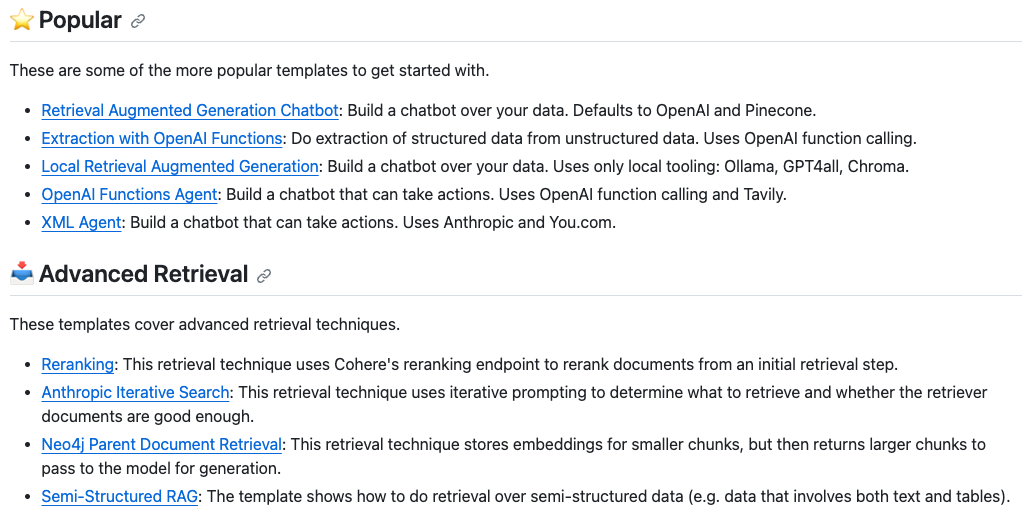
利用可能なテンプレートの一覧はこちらから確認できます。今回は、その中の1つであるRAGのテンプレートを使ってアプリケーションを構築してみましょう。
RAGの構築
環境のセットアップ
まず、LangChain CLIをインストールします。このパッケージを使うことで、LangChainアプリケーションを作成したり、作成したアプリケーションからサーバーを起動したりできます。
pip install -U langchain-cli
また、OpenAIのモデルを使うので、OpenAIのAPIキーを環境変数に設定しておきましょう。
export OPENAI_API_KEY=xxx
RAGの実装
次に、インストールしたCLIを使って新しいアプリケーションを作成します。このとき、--packageオプションにテンプレート名を指定することで、新しいアプリケーションの作成時に指定したテンプレートが追加されるようになります。今回はRAGを構築したいので、rag-chromaと指定しています。
langchain app new rag-example --package rag-chroma
コマンドが正常に実行されると、以下のような構成になっているrag-exampleディレクトリが作成されます。packagesディレクトリの下には、rag-chromaという名前のパッケージが追加されています。このパッケージには、RAGの実装が含まれています。また、app/server.pyにはサーバーを立ち上げるためのコードが含まれています。
❯ tree rag-example rag-example ├── Dockerfile ├── README.md ├── app │ ├── __init__.py │ └── server.py ├── packages │ ├── README.md │ └── rag-chroma │ ├── LICENSE │ ├── README.md │ ├── poetry.lock │ ├── pyproject.toml │ ├── rag_chroma │ │ ├── __init__.py │ │ └── chain.py │ ├── rag_chroma.ipynb │ └── tests │ └── __init__.py └── pyproject.toml
server.pyを編集して、以下のコードを追加します。こうすることで、サーバーを立ち上げた後、ブラウザ上からアプリケーションの動作を確認できるようになります。add_routes(app, NotImplemented)の部分をコメントアウトし忘れないようにしましょう。
from rag_chroma import chain as rag_chroma_chain # add_routes(app, NotImplemented) add_routes(app, rag_chroma_chain, path="/rag-chroma")
また、デフォルトだと対象としている文書が英語用なので、日本語に対応できるように書き換えます。rag_chroma/chain.pyを開き、ファイルを編集します。デフォルトだと、トリプルクオテーションでコメントアウトされている箇所があるので、それを解除した後、以下のようにコードを書き換えます。以下では対象文書を日本語Wikipediaの東京都のページに置き換えています。
from langchain.document_loaders import WebBaseLoader # loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/") # data = loader.load() loader = WebBaseLoader("https://ja.wikipedia.org/wiki/東京都") data = loader.load()
次に、不要なコードをコメントアウトします。
# Embed a single document as a test # vectorstore = Chroma.from_texts( # ["harrison worked at kensho"], # collection_name="rag-chroma", # embedding=OpenAIEmbeddings(), # ) # retriever = vectorstore.as_retriever()
依存関係が定義されたファイルがあるので、この時点で必要なパッケージをインストールしましょう。
cd rag-example pip install beautifulsoup4 pip install -e .
RAGの動作確認
これで準備が完了したので、サーバーを起動します。
langchain serve
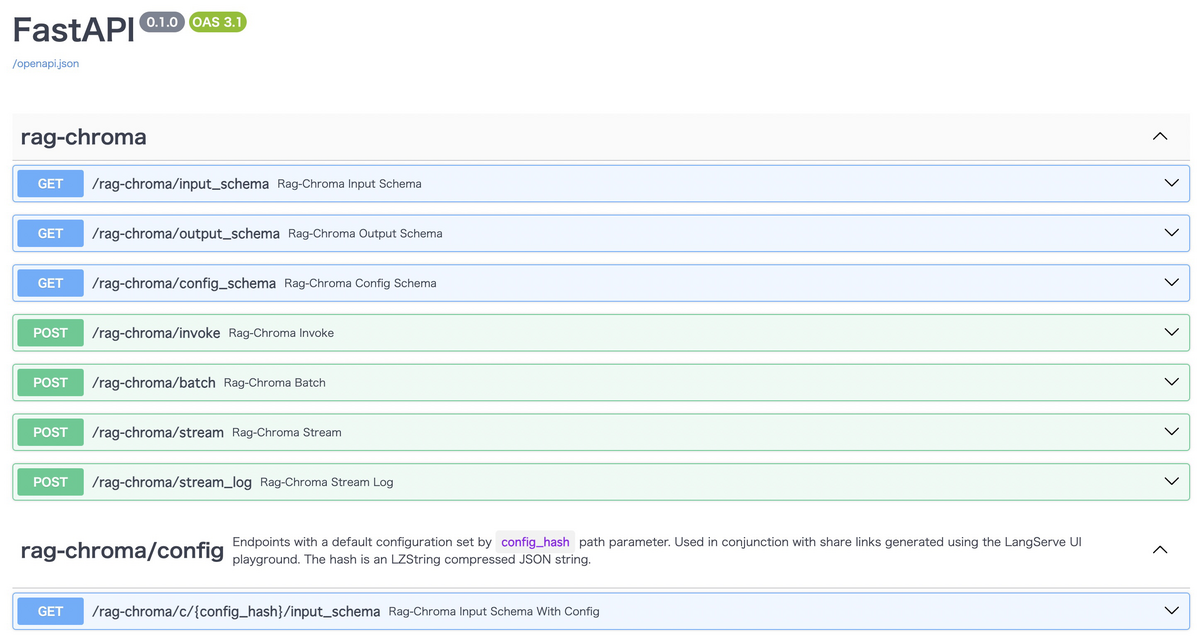
サーバーの起動後、http://127.0.0.1:8000/docsにアクセスすると、以下のような画面が表示されます。ここには、各エンドポイントの情報が記載されているので、プログラムからアクセスする際に役立ちます。
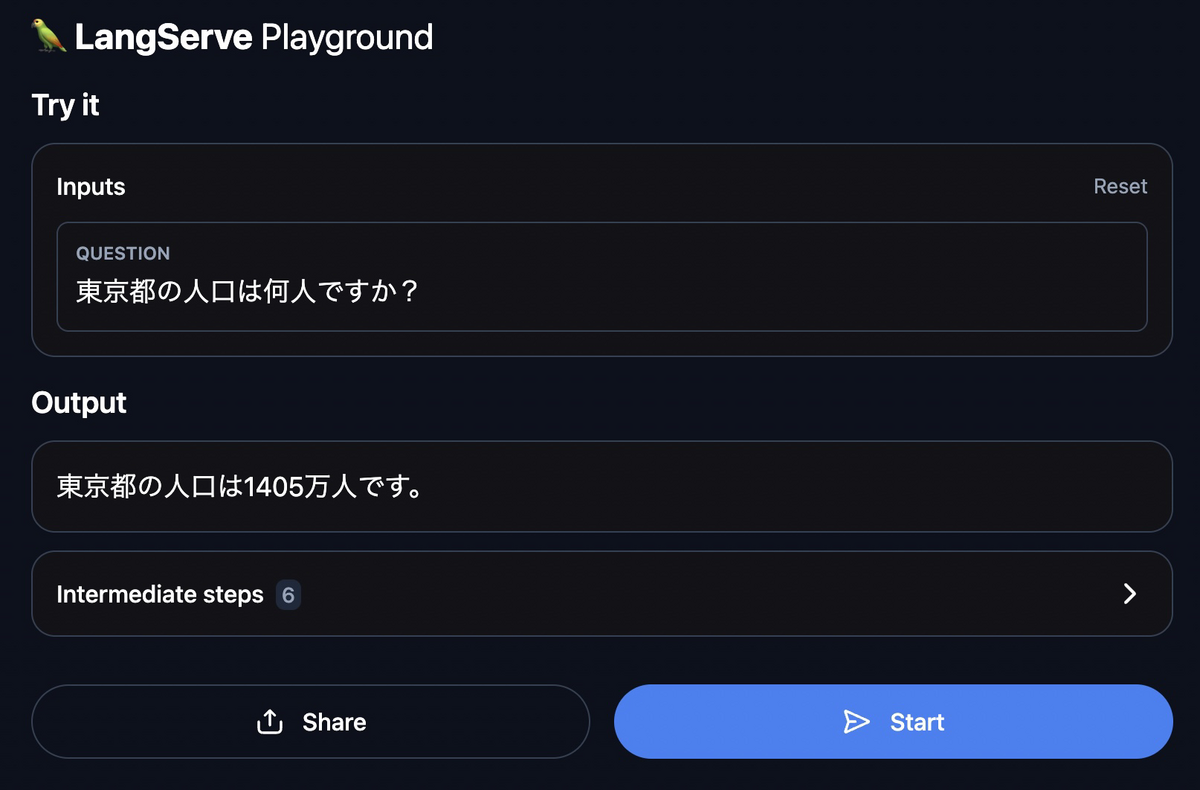
RAGの動作を確認するには、http://127.0.0.1:8000/rag-chroma/playground/にアクセスします。ここには、RAGの動作を確認するためのフォームが表示されています。ここで、質問文を入力すると、RAGが回答を生成してくれます。試しに「東京都の人口は何人ですか?」と入力してから「Start」ボタンを押すと、「東京都の人口は1405万人です。」という回答を返してくれました。
以上でRAGの実装は完了です。
おまけ:研究アシスタントの構築
おまけとして、LangChain Templatesを活用し、研究アシスタントを作成する方法を紹介します。この研究アシスタントは、リサーチクエスチョンを入力すると、文書を検索し、レポートにまとめてくれる機能があります。以下はその例です。

研究アシスタントのアーキテクチャは以下のとおりです。大きくは、ユーザーが入力したリサーチクエスチョンから検索クエリを生成し、各クエリで検索した情報を要約してから結合し、レポートを生成しています。要約を結合してからLLMに入力しているため、それなりに長いコンテキスト長を扱えるモデルを使う必要があります。
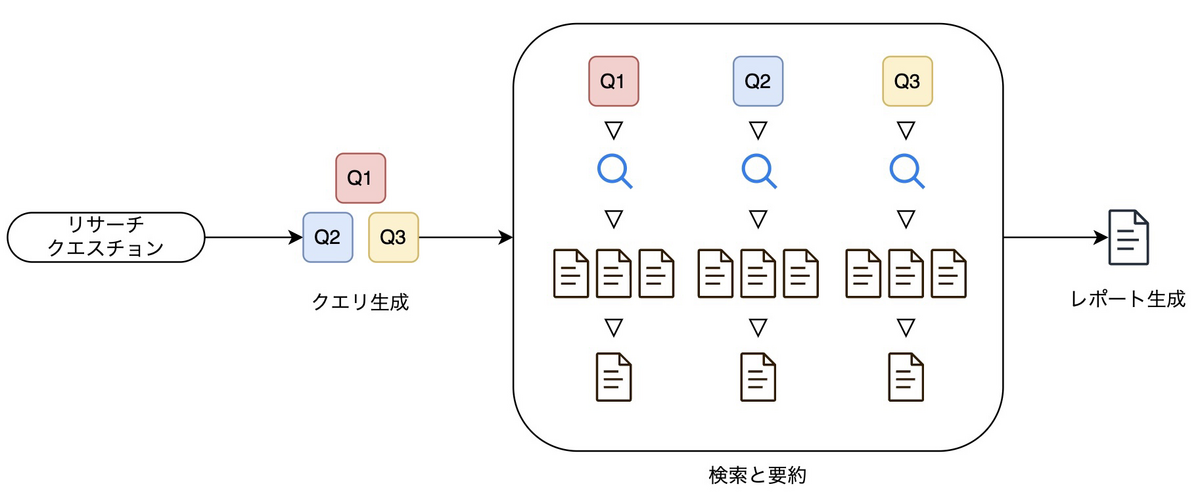
研究アシスタントの動作
研究アシスタントには、リサーチクエスチョンを入力します。デフォルトだと検索エンジンとしてDuckDuckGoを使いますが、この部分は変更可能です。
使うモデルや出力の量にもよりますが、3〜5分程度でMarkdown形式のレポートが出力されます。
レポートは参考文献付きです。なぜか連番ではありませんでしたが、LLMにはよくあることでしょう。

研究アシスタントの実装
前提として、OpenAIのモデルを使うことが想定されているため、環境変数を設定しておきます。
$ export OPENAI_API_KEY="YOUR API KEY"
まず、LangChain CLIをインストールします。
$ pip install -U langchain-cli
次に、インストールしたCLIを使って新しいLangChainプロジェクトを作成します。このとき、--packageオプションにパッケージ名を指定することで、そこに研究アシスタントをパッケージとしてインストールします。
$ langchain app new my-app --package research-assistant
そうすると、以下のようなディレクトリ構成になっているはずです。依存関係が定義されたファイルがあるので、この時点で必要なパッケージをインストールしておきましょう。
$ tree . ├── Dockerfile ├── README.md ├── app │ ├── __init__.py │ └── server.py ├── packages │ ├── README.md │ └── research-assistant │ ├── LICENSE │ ├── README.md │ ├── poetry.lock │ ├── pyproject.toml │ ├── research_assistant │ │ ├── __init__.py │ │ ├── chain.py │ │ ├── search │ │ │ ├── __init__.py │ │ │ └── web.py │ │ └── writer.py │ └── tests │ └── __init__.py ├── poetry.lock └── pyproject.toml
server.pyに以下のコードを追加します。
from research_assistant import chain as research_assistant_chain add_routes(app, research_assistant_chain, path="/research-assistant")
準備が完了したので、CLIからサーバーを起動します。
$ langchain serve
http://127.0.0.1:8000/research-assistant/playgroundから、アシスタントを使うことができます。
研究アシスタントの内部処理
ここでは、以下の処理の詳細について説明します。
- クエリ生成
- 検索と要約
- レポート生成
クエリ生成では、リサーチクエスチョンとエージェントのロールを入力とし、検索クエリを3つ生成します。デフォルトだとDuckDuckGoで検索しますが、プロンプト的にはGoogle検索用のクエリを生成しています。この2つでクエリが大きく異なることはなさそうなので問題ないでしょうが、対象とする検索エンジンやタスクによっては別途フィルタリングをかけたりしたいことがあるので、その場合はカスタマイズする必要があるでしょう。
検索と要約では、生成したクエリを使って検索をし、その結果をスクレイピングしたあと、要約をしています。検索する文書数は各クエリに対して3つなので、クエリ数との掛け算で9つの文書が得られます。得られた文書は要約され、以下のように情報源のURLと要約からなるテキストにまとめられます。これが次のレポート生成の入力の1つになります。
Source Url: https://arxiv.org/abs/2311.03754 Summary: The paper "Which is better? Exploring Prompting Strategy... Source Url: https://dzone.com/articles/maximizing-the-potential-of-llms-a-guide-to-prompt Summary: The text discusses various prompt engineering strategies... Source Url: https://link.springer.com/article/10.1007/s11528-023-00896-0 Summary: The text explores the transformative potential of Large... ...
レポート生成では、リサーチクエスチョンと要約結果を入力とし、レポートを生成します。レポート生成のプロンプトでは、レポートの最後に参考文献のURLを重複無しで記載するように記載されているため、参考文献付きで出力されるようになっています。連番にするような指示は特にないので、プロンプトを書き換えることで出力を改善できる可能性はあります。