生成したテキストをGPT-4で評価している論文
最近は、ChatGPTやGPT-4に関する記事が多数公開されています。とくに、自社の持つ文書に対して問い合わせをし、そこから回答を抽出したり、要約を生成するようなユースケースを見かけることが多い気がしています。こういったユースケースの場合、伝統的な評価指標(再現率・適合率、F1、BLEU、ROUGEなど)やオンライン評価以外だと、どのように評価できるのか気になって以下の論文を読んだので、簡単にまとめます。
概要
- 一般的に使われる指標だと次の問題がある
- 人間による評価との相関が弱い(とくにオープンエンドな生成の場合)
- 人間が正解を用意する必要があるので、そのコストが高い
- 問題解決のために、大規模言語モデル(GPT-3.5、GPT-4)を使った評価手法を提案
- テキスト要約と対話生成で評価した結果、人間の評価との相関が先行研究を大きく上回った
手法
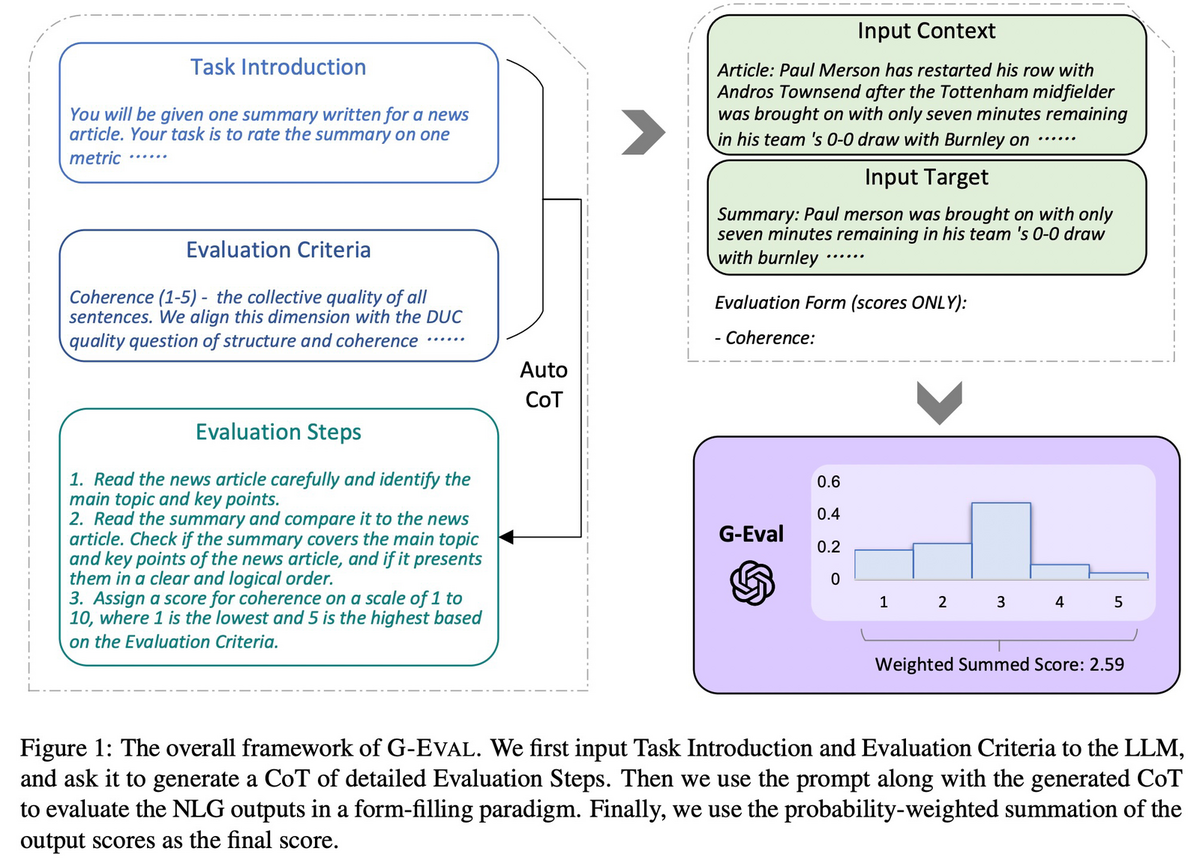
3つのコンポーネントから構成されている。
- プロンプト:評価タスクの定義と評価基準を含む(下図のTask Introduction & Evaluation Criteria)。
- CoT:詳細な評価ステップを記述する(下図のEvaluation Steps)。LLMに自動で書かせる。
- スコア関数:モデルに出力させたスコアをそのまま使うのではなく、LLMが出力したトークンの確率からスコアを計算(下図の右下)。
実験設定
- SummEval
- Topical-Chat
- QAGS
モデル
- GPT-3.5(davinci)
- GPT-4
※GPT-4だとトークン確率が得られないため、20回サンプリングして確率を推定
比較対象
- BERTScore
- MoverScore
- BARTScore
- FactCCとQAGS
- USR
- UniEval
- GPTScore
評価結果
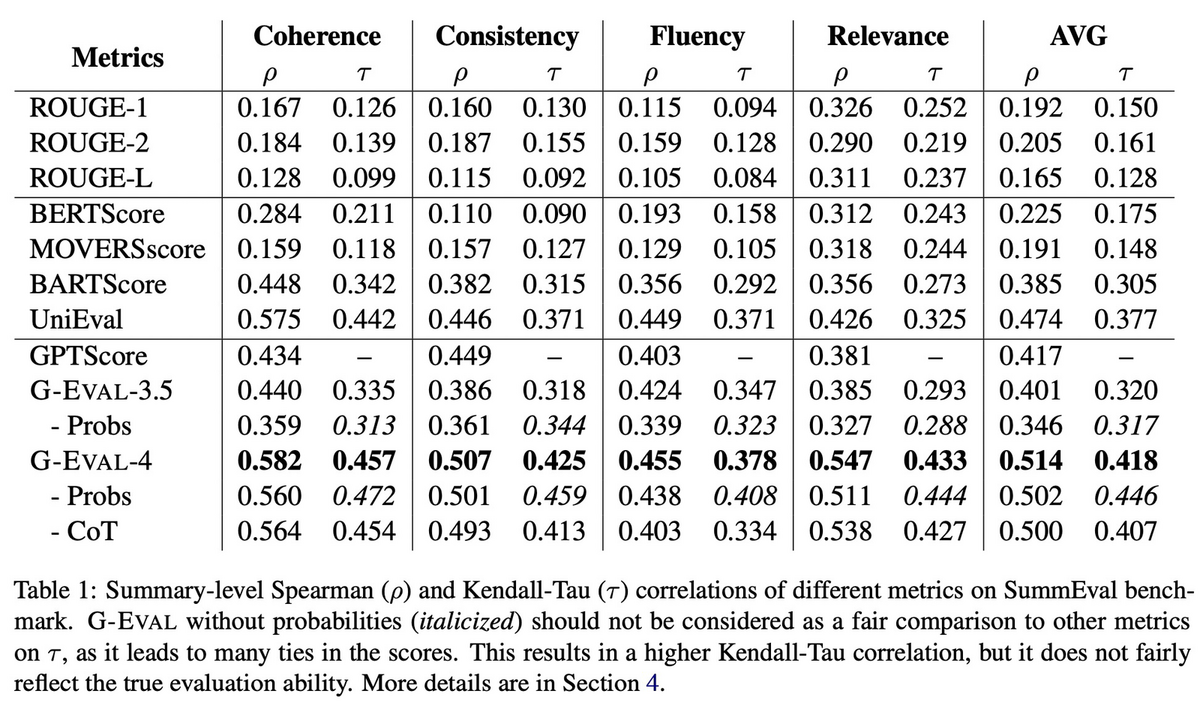
SummEvalの評価結果だけ以下に示す。
- 提案手法は、人間による評価との相関がより強い
- CoTを入れた場合の方が、とくにFluencyの性能は高い
- トークンの確率を正規化すると、改善することもある
感想
- 実際にどのくらい使えるかはわからないが、正解を用意する必要がないのは魅力的
- 方法は違うが、Llama Indexにも評価用コンポーネントがあるので、カスタマイズすれば実装できる、はず
- 他にいくつか手法を調べる&実際に試してみたいところ