Rewrite-Retrieve-Readの論文[1]の構成で検索性能が改善するか試してみました。内容としては、RAGの内部で検索するときに、ユーザーのクエリを書き換えると性能が上がるという話です。ユーザーのクエリが検索に適しているとは限らないため、LLMで書き換えてから検索しようというアイデアになります。論文では、強化学習を使って書き換え用のモデルを学習する検証もしていますが、既存のLLMに書き換えさせても効果があるという結果になっています。
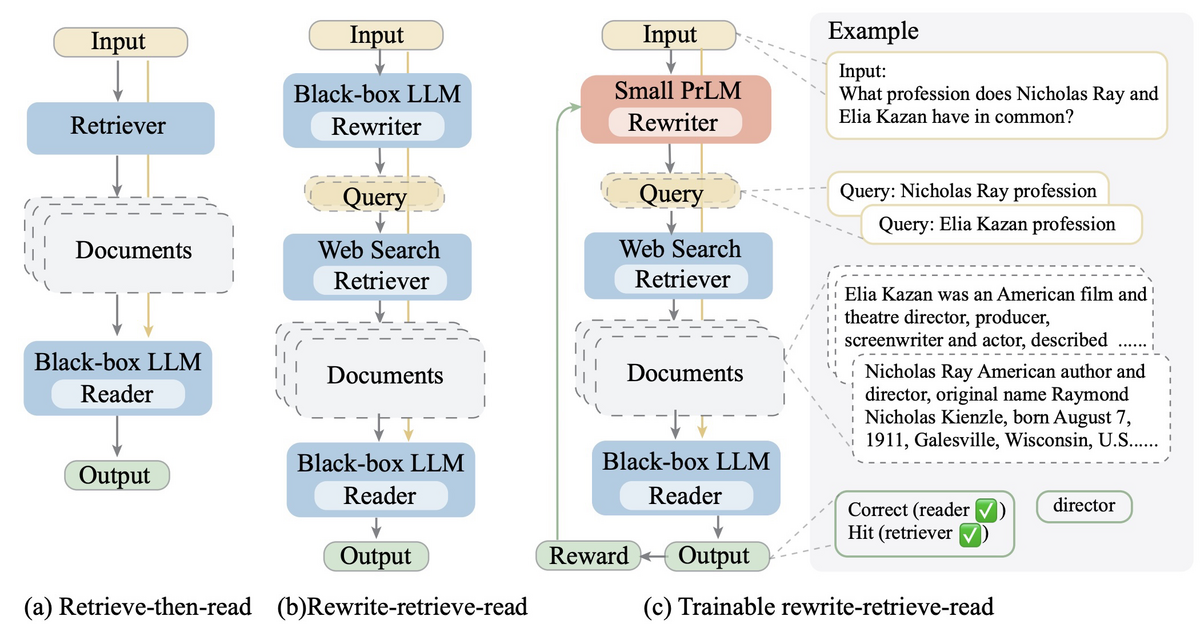
本実験では、GPT-3.5 Turboを利用して、元のクエリを書き換えたときの検索性能の検証結果を紹介します。このアプローチが、実際の検索シナリオでどのように機能するかを、日本語のQAデータセットを用いて評価しました。記事の構成は以下のとおりです。
実験設定
今回の実験では、LLMを用いて書き換えたクエリを使って検索することで、検索性能がどのように変化するかを検証します。クエリ生成にはGPT-3.5 Turboを使用し、以下のプロンプトを用いてクエリを書き換えています。なお、再現性を高めるために、GPT-3.5 Turboのtemperatureには0を設定しています。LangChain Hubにあるプロンプトをベースにしていますが、そのまま使うと英語で書き換えてくることや複数のクエリを返してくることがあるので、少し変更しています。
Provide a better search query in Japanese for web search engine to answer the given question. Question {x} Answer:
上記のプロンプトを使ってクエリを書き換えた例を以下に示します。元のクエリを端的に言い換えていることがわかります。ちなみに、尼崎市に対して思うところはないので誤解なきように。
元のクエリ: 正直言って、尼崎市のイメージは良くないと思うのですが、市のブランドイメージ向上の為の具体的な施策はありますか?
書き換えたクエリ: 尼崎市のブランドイメージ向上のための具体的な施策は何かありますか?
検索器としてはキーワード検索とベクトル検索を使用します。キーワード検索にはBM25、ベクトル検索にはOpenAIのtext-embedding-ada-002を使っています。どちらもLangChainの実装[2][3]を使用しており、BM25についてはパラメーターとしてk1に1.5、bに0.75を設定し、トークナイザーにはMeCabを採用しました。また、ベクターストアとしてはFAISSのデフォルト設定を採用しました。
評価用のデータセットとしては、尼崎市のQAデータ[4]を使用します。このデータセットには、784の質問に対して対応する回答がAからCの3つのカテゴリでラベル付けされています。Aの場合は正しい情報を含み、Bであれば関連する情報を含み、Cであればトピックが同じであることを意味します。今回はこれらのカテゴリを関連文書として扱うことにします。
評価については上位10件のヒット率とMRR(Hit Rate@10、MRR@10)でします。
実験結果
評価結果は以下のとおりです。キーワード検索の場合は性能が改善する一方、ベクトル検索の場合は性能が低下するという結果になりました。クエリを書き換えたことで、元のクエリに関連するものの、意図が異なるクエリになったために性能が低下した可能性がありそうです。また、数は多くありませんが、クエリを書き換えた際にキーワード区切りのクエリが生成されることがあるので、そのような場合に埋め込みモデルが良い表現を生成できているか確認する必要があります。
| モデル | Hit Rate@10 | MRR@10 |
|---|---|---|
| BM25 | 0.5918 | 0.3955 |
| BM25 + Rewrite | 0.6147 | 0.4202 |
text-embedding-ada-002 |
0.8355 | 0.6436 |
text-embedding-ada-002 + Rewrite |
0.8329 | 0.6211 |
text-embedding-ada-002 + Rewrite + Original |
0.8520 | 0.6374 |
意図が異なるクエリに書き換えられた場合の影響を緩和するため、元のクエリで検索した結果と書き換えたクエリの結果をRRFを使ってアンサンブルした結果を表の一番下に記載しました。結果を見ると、Hit Rate@10とMRR@10ともに書き換えたクエリだけを用いた場合と比べて改善していることがわかります。書き換えることで失われる情報もあるので、使う際には元のクエリと併用したほうが良い可能性があります。
実装の詳細
クエリを書き換え、書き換えたクエリで検索するためには、LangChainのRePhraseQueryRetriever[5]を使うことができます。この検索器は、クエリが与えられたら、LLMを使ってクエリを言い換えます。そして、ベースとなる検索器に対して言い換えたクエリを使って文書を取得します。以下のように、書き換え用のプロンプトを定義して渡すだけで、書き換えたクエリを使って検索できます。
from langchain.chat_models import ChatOpenAI from langchain.retrievers.bm25 import BM25Retriever from langchain.retrievers.re_phraser import RePhraseQueryRetriever from langchain.prompts.prompt import PromptTemplate # 書き換え用モデルの用意 llm = ChatOpenAI(temperature=0) # プロンプトの定義 rewrite_template = "Provide a better search query in Japanese for web search engine to answer the given question. Question {x} Answer:" rewrite_prompt = PromptTemplate.from_template(rewrite_template) # 検索器の用意 base_retriever = BM25Retriever.from_documents(...) retriever = RePhraseQueryRetriever.from_llm( retriever=base_retriever, llm=llm, prompt=rewrite_prompt )
なお、実験では変換後のクエリを使いまわしたかったため、RePhraseQueryRetrieverの外側でクエリの変換をしています。
今回の検証では、強化学習を使ってクエリ書き換え用のモデルを学習したわけではないので、基本的には以下の記事で検証したマルチクエリ生成の特殊な場合と考えられます。結果の傾向も似ているため、以下の記事と合わせて読むことをおすすめします。