部分的にアノテーションされたデータからの固有表現認識器の学習
固有表現認識は、テキスト中に含まれる人名や地名、組織名といった固有表現を自動的に認識する技術です。たとえば、「太郎は10時30分に東京駅に着いた」というテキストからは、人名として「太郎」、時間として「10時30分」、地名として「東京駅」を認識できます。固有表現認識は、情報抽出や情報検索、質問応答などの自然言語処理のアプリケーションで広く利用されています。

最近では、固有表現認識でも教師あり学習を用いた手法が主流となっていますが、ラベル付きデータは人手で用意するのが一般的なので、十分な量を用意するためには相応のコストがかかります。とくに固有表現認識の場合、分類タスクと比較すると、単語や文字ごとにラベル付けするため、用意するのは大変です。
アノテーションコストを減らすため、部分的にアノテーションされたデータの活用が考えられます。部分的にアノテーションされたデータとは、データセットの一部分だけにアノテーションされたデータのことです。たとえば、冒頭の例で言えば、「太郎」と「東京駅」のみにアノテーションされていれば、それは部分的にアノテーションされたデータと言えます。このようなデータは固有表現辞書やルールによって作成できます。
辞書やルールで部分的にアノテーションするだけでもよいのですが、こうして作成したデータからモデルを学習する方法も考えられます(下図)。一般的に、辞書を用いたアノテーションでは、辞書に格納されている固有表現とテキストをマッチングします。この方法は、精度は高いのですが、辞書サイズが小さかったり表記ゆれがある場合、再現率が低くなるのが欠点です。そのため、直接的に使うのではなく、いったんモデルに学習させます。
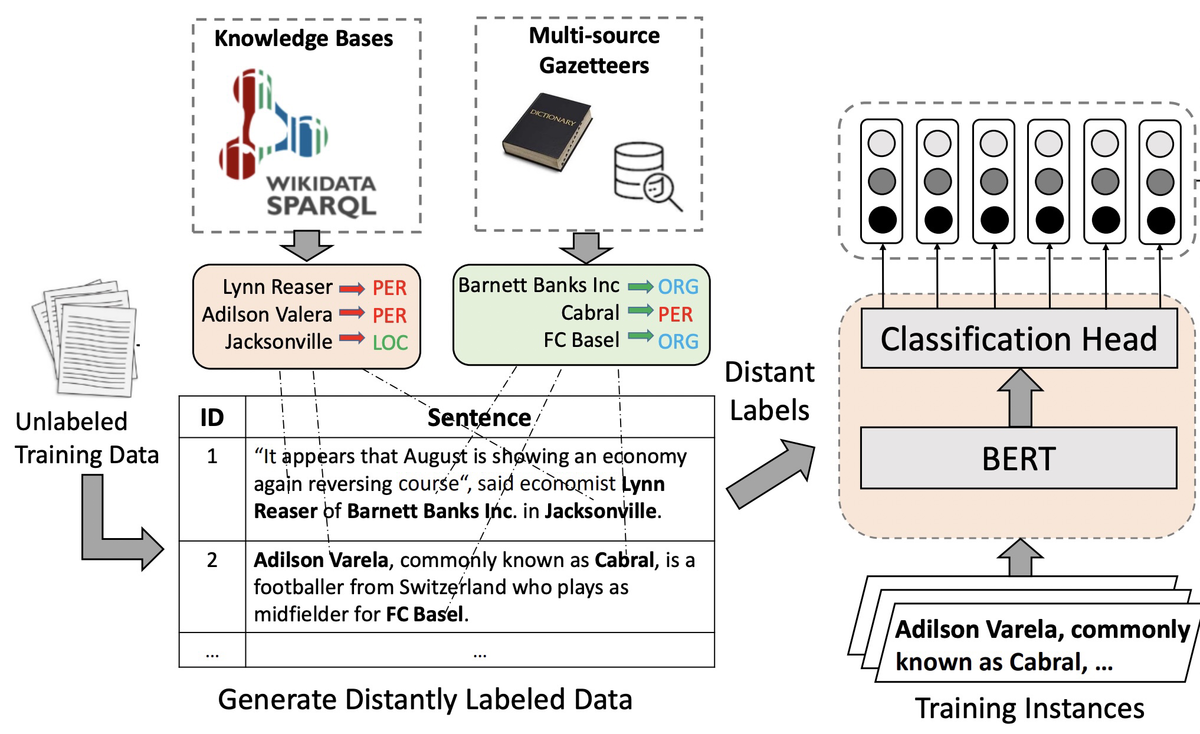
部分的にアノテーションされたデータをモデルに学習させる場合、本来は固有表現があるべき場所にないこと(タグの欠落)が問題になりえます。通常の教師あり学習では、このような状態を考慮していないため、学習が上手く進まず、性能が低くなると考えられます。辞書を用いてアノテーションしたデータの場合、とくに再現率が低くなると考えられます。
この問題に対処するために、2021年のTACLでは期待固有表現比率(Expected Entity Ratio:EER)と呼ばれる損失が提案されました[2]。この手法では、データセット全体での固有表現の出現割合が一定の範囲内になるように、モデルを学習します。この損失を組み込むことで、タグが欠落している場合にもなるべく固有表現の予測を試みてくれます。
では、実際にEERを組み込んだモデルを試してみましょう。
実験
検証内容
今回は、辞書データを用いてアノテーションしたデータに対して、EERを組み込んだモデルの性能を検証します。実際の状況では、辞書サイズが限られている場合もあると考えられるため、辞書サイズを25~100%まで25%ずつ変化させたときの性能を検証します。実装としては、EERのspaCy実装であるspacy-partial-taggerを利用します。
固有表現認識用のデータセットとしては、BC5CDRを使います。このデータセットは医療系のデータセットであり、固有表現としては「Chemical」と「Disease」の2つが付いています。また、辞書としては先行研究で公開されているものを使用します。この辞書に登録されている固有表現数は2482件です。
事前学習済みモデルとしては、Microsoftが公開しているPubMedBERTを使用します。このモデルはPubMedのテキストで学習されているため、今回のデータセットに適していると考えられます。
以下の4つのモデルについての性能を見てみましょう。
- 完全な教師データで学習したPubMedBERTモデル(Fully supervised)
- 部分的にアノテーションされたデータで学習したPubMedBERTモデル(PubMedBERT)
- 部分的にアノテーションされたデータで学習したPubMedBERT + EERモデル(+EER)
- 辞書マッチ(Dictionary Match)
検証結果
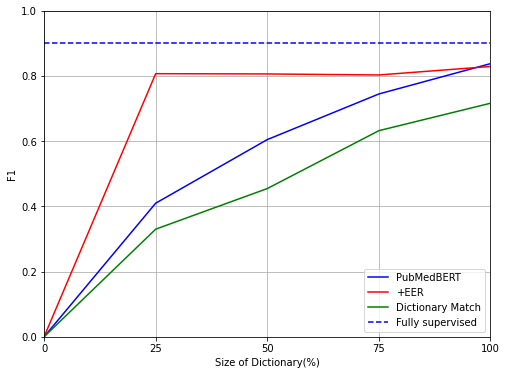
検証結果は次のとおりです。今回の場合は、辞書マッチの結果をそのまま使うよりも、いったんモデルに学習させたほうが性能が高いことがわかります。また、EERを使うことで、とくに辞書サイズが小さな場合に性能が向上していることがわかります。これは主に再現率が向上しているためです。また、Fully supervisedと比べると、7ポイントほど性能が低いという結果になりました。
終わりに
本記事では、部分的にアノテーションされたデータから固有表現認識モデルを学習する方法としてEERを検証しました。実験の結果、今回のデータセットと辞書の組み合わせでは、とくに辞書サイズが小さな場合でのEERの有効性を確認できました。辞書からはランダムにサンプリングしており、どんな場合でも有効とは限りませんが、固有表現辞書とアノテーション対象のテキストが用意できる場合には利用することを検討してみます。